做过两年自动化测试的小伙伴说web自动化测试真的不难,无非就是一些浏览器操作,页面元素操作,常规的情况很容易处理,再学一学特殊元素的处理,基本就能应付项目的测试了。
这个话倒没错,但是真正要学好自动化测试,深入自动化,并不是那么简单。
首先你得懂原理吧,原理不懂,你就不知道怎么解决一些异常情况,也无法完成拓展。
其次你得学会写自己的测试框架吧,一个项目写了100个测试类,都是零散的脚本,没有任何设计而言,都是纯粹的业务代码,那我可以说,换了项目你这些脚本就成了垃圾。
因此,我们要做自动化,要成为自动化大牛,就一定要花时间去要搞清楚自动化实现的原理,并且学会自己去实现自动化测试框架,乃至于自动化测试平台。
下面一段代码实现了一个很简单的功能:
1、打开浏览器
2、访问页面“http://ke.qq.com”
3、定位到页面的搜索框
4、输入查询数据
5、定位搜索按钮
6、点击搜索按钮,完成搜索
代码如下图:

驱动文件位置:
需求很简单,代码也很简单。
但是你知道代码中的这些浏览器操作,元素操作,是如何完成的吗?
比如,浏览器启动完成后,再调用:driver.get("https://ke.qq.com/");
就能在导航栏中访问到指定的这个页面,这个里面发生了什么?
到底是客户端脚本直接操作浏览器还是通过某些中间件来完成??
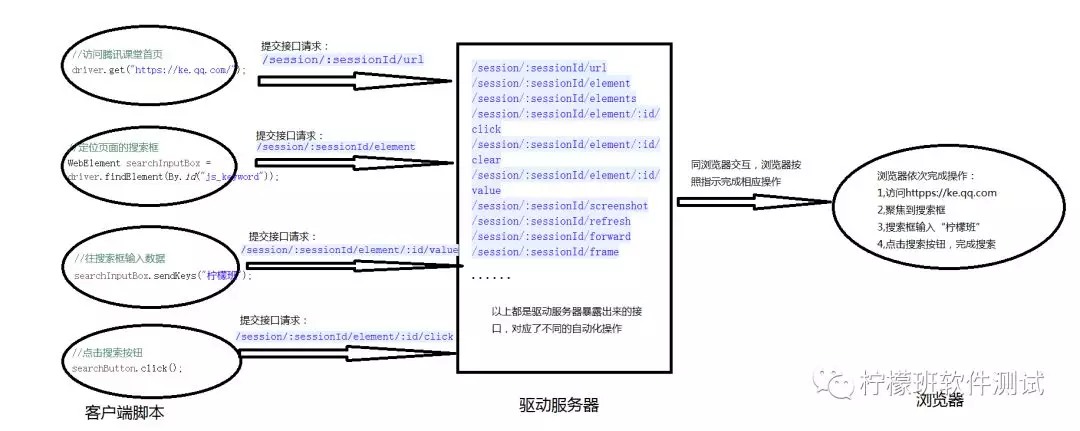
底层原理如下:
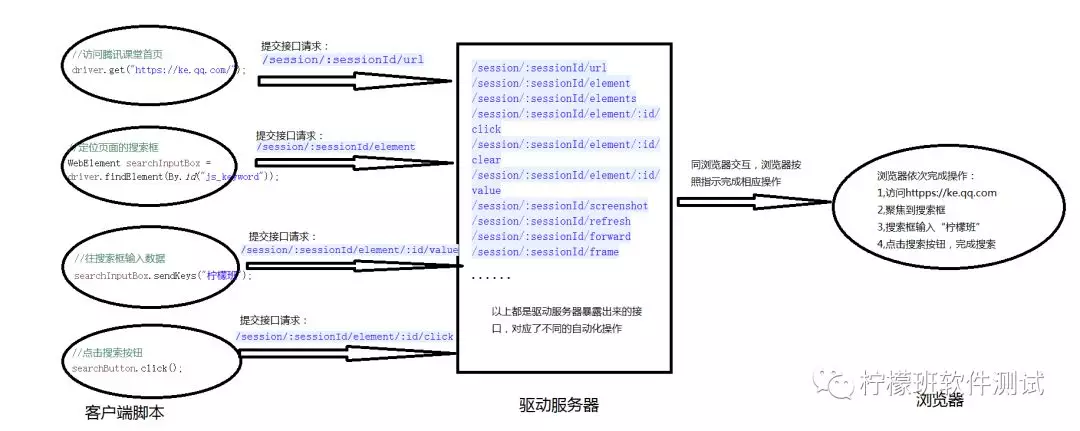
1、在自动化测试过程中,存在三部分组件:客户端脚本+驱动+浏览器终端。
2、驱动文件,以geckodriver.exe为例,这个可执行的驱动文件启动后,相当于一个暴露了一系列接口的服务器,监听某一端口,例如:89890。
3、客户端的操作(访问页面,定位元素,输入数据,点击按钮等)都是封装成了接口请求(eg:/session/xx/yy),然后提交到驱动服务器。
4、驱动服务器接收到客户端的请求后,再跟终端浏览器交互。
5、终端浏览器做出相应操作。
下图描述了整个交互过程:
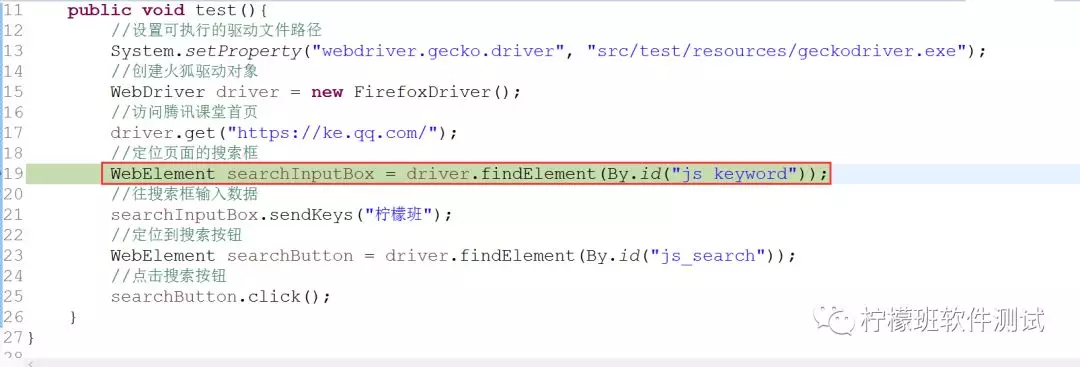
以定位元素为例,定位搜索框,我们来看底下这行代码在执行的时候底层到底经历了些什么:
实际,底层请求时,每个请求会被封装为一个command,然后根据不同的commannd封装得到不同的HttpRequest对象:
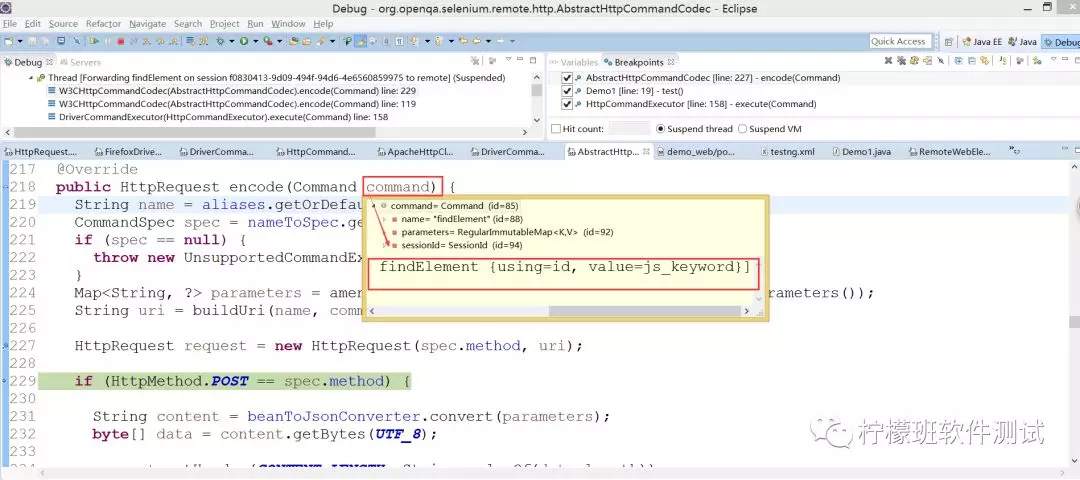
根据此命令,得到接口地址:
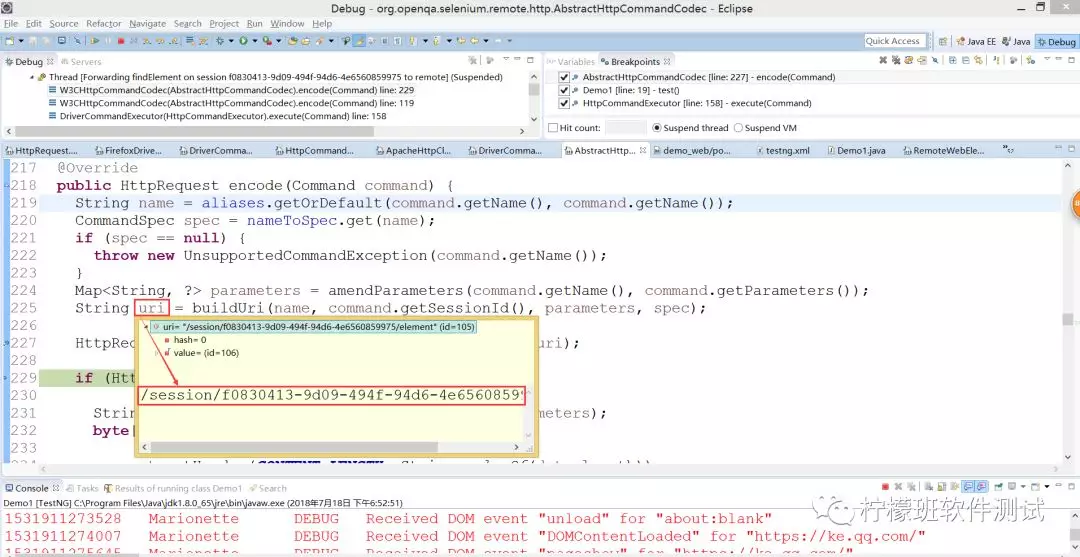
拿到此接口地址封装为一个HttpRequest请求。
client.execute(httpRequest,true),执行接口调用:
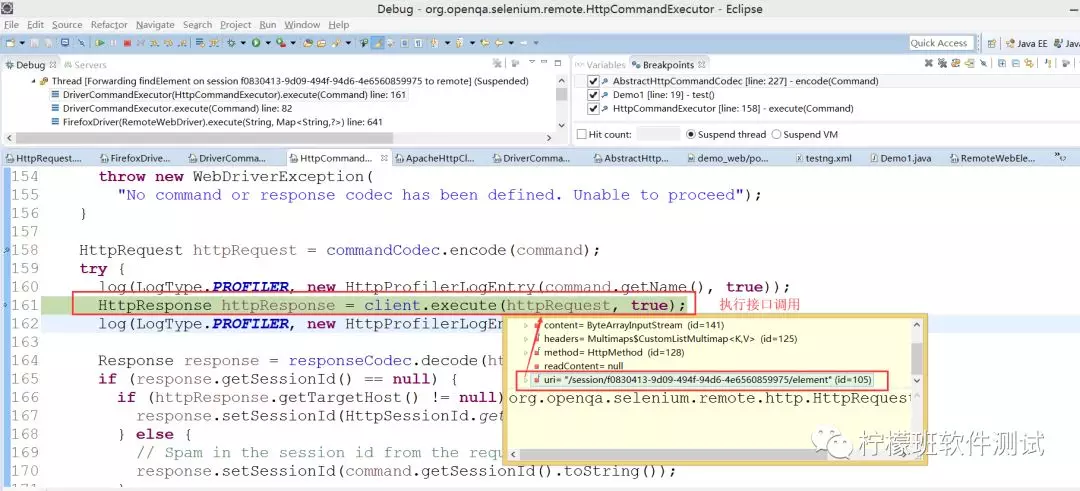
至于其他操作:往输入框输入数据,点击按钮等,都是对应一个接口地址,通过调用接口,请求驱动来处理,最后驱动同浏览器进行交互,浏览器按照指示做出对应操作。
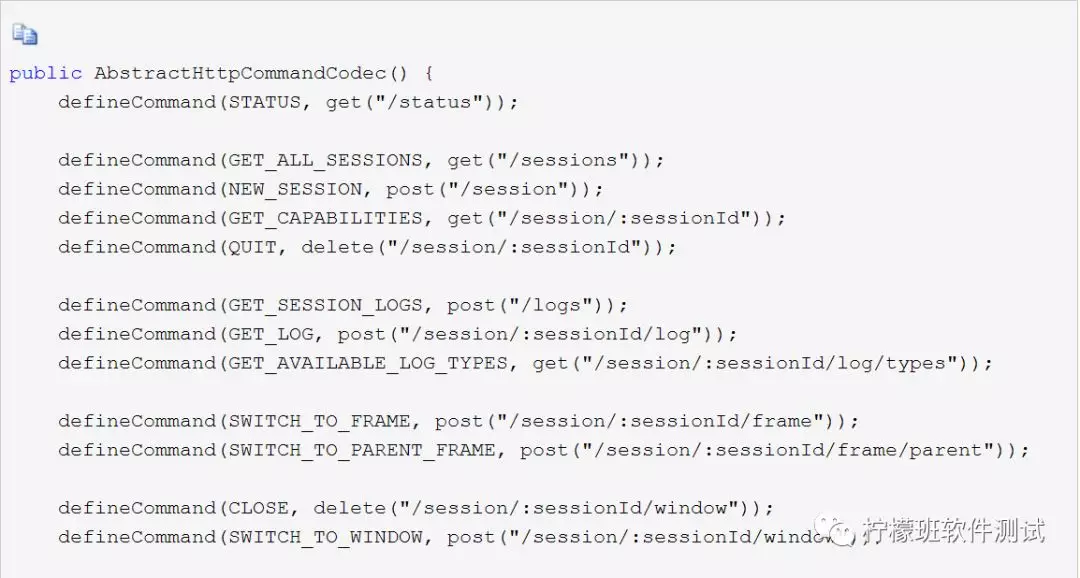
Selenium有一个类AbstractHttpCommandCodec,此类中维护了众多自动化操作对应的接口地址:

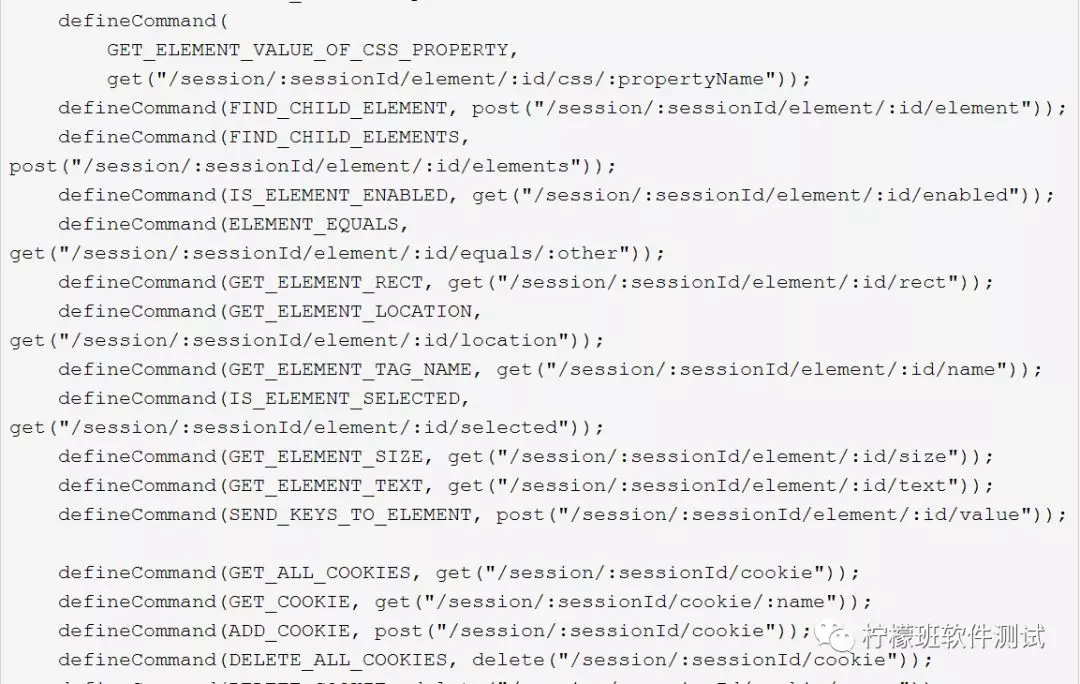

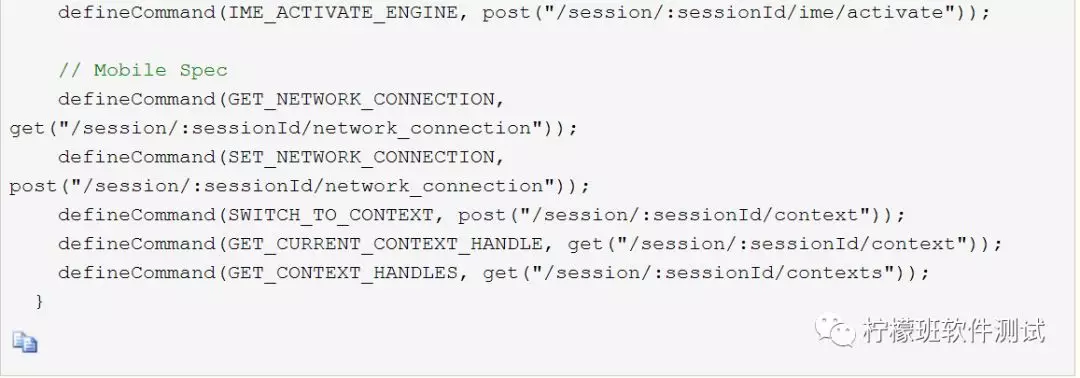
另外,可能会有人好奇,驱动服务器是何时启动的服务。其实是在执行下面这行代码的时候启动的,大家可执行去debug调试selenium的底层代码:

当上面这行代码执行完,可以发现eclipse的控制台显示了如下信息:

说明此驱动服务器成功启动了,并且监听了本机的21984端口,等待客户端发起请求,并处理。
至于驱动跟浏览器之间是如何交互的,在后面的文章中会择机介绍,请大家守候。
欢迎来到testingpai.com!
注册 关于