在网上总是很难找到令自己比较满意的,关于正则表达式的文章。所以决定自己来总结一波,并配上相应的示例。
正则表达式:定义了规则,用来字符串处理。
用途:
- 匹配 - 符合规则的字符串,则认为匹配了。
- 提取 - 提取出符合规则的字符串。
python中通过re模块来处理正则表达式。re模块的常用方法如下:
re.match(re规则,字符串):从头开始匹配。从字符串的第一个字符开始匹配,如果第一个字符不匹配规则,那么匹配失败。
re.search(re规则,字符串):匹配包含。不要求从字符串的第一个字符就匹配。只要字符串当中有匹配该规则的,则就匹配成功。
re.findall(re规则,字符串):把所有匹配的字符放在列表中并返回。
re.sub(re规则,替换串,被替换串):匹配字符并替换。
正则表达式常用的规则如下:
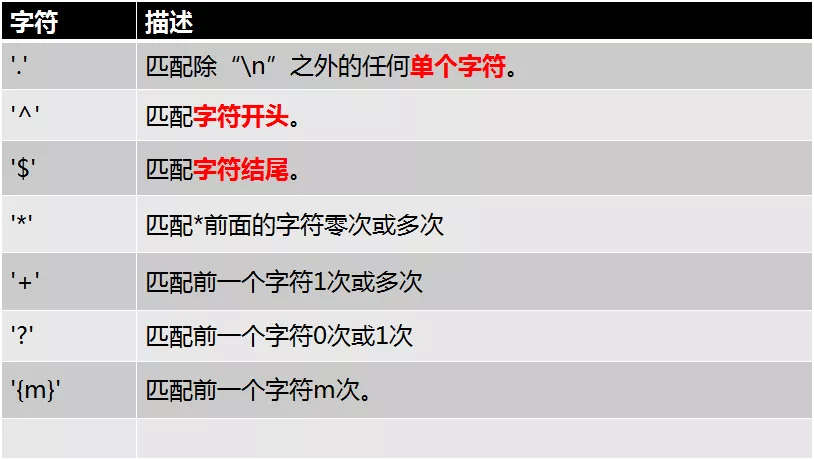
下面一一示例来说明:
'.' : 是只匹配一个字符(除了\n)
如字符串a="hello123world!!" , 那么'.'匹配到的结果为:"h" .从字符串a中搜索,搜索什么呢,符合规则'.'的数据。

'^' : 匹配字符串的开头。指定字符串必须以什么开头,如果不一样,则匹配失败。
如字符串a="hello123world!!" , 那么'^h'匹配到的结果为:"h" .如果是'^F'则匹配失败

re.match方法也是从字符串开头匹配。所以与^效果一样:

'':指定字符串以前的字符结尾 。

'*':表示匹配前面的字符 0次 或者 多次
'+':表示匹配前面的字符 1次 或者 多次
以上的所有匹配都只是匹配到了一个字符。那这两个匹配符则可以匹配多次。

如果我想要指定匹配次数呢? -----
'{m}':指定匹配前面字符的次数。

如果只考虑匹配 0次 或者 1次呢 ---
'?':表示匹配前面的字符 0次 或者 1次

今天的分享就到这里了!
欢迎来到testingpai.com!
注册 关于