在robotframework当中,要实现web自动化,则需要使用SeleniumLibrary这个库。
目前版本中,有180+关键字。随着版本的更新,关键字的个数和名字也会有所变动。
在网上没有找到较为全面的关于这个库的关键字介绍,所以此篇文章按照关键字类别,列举常用的关键字,作为参考工具。
1、SeleniumLibrary的安装:
前提:已安装好python环境并配置好环境变量。然后在命令行当中,运行以下命令:
pip install --upgrade robotframework-seleniumlibrary
2、SeleniumLibrary结构、和Selenium的关系
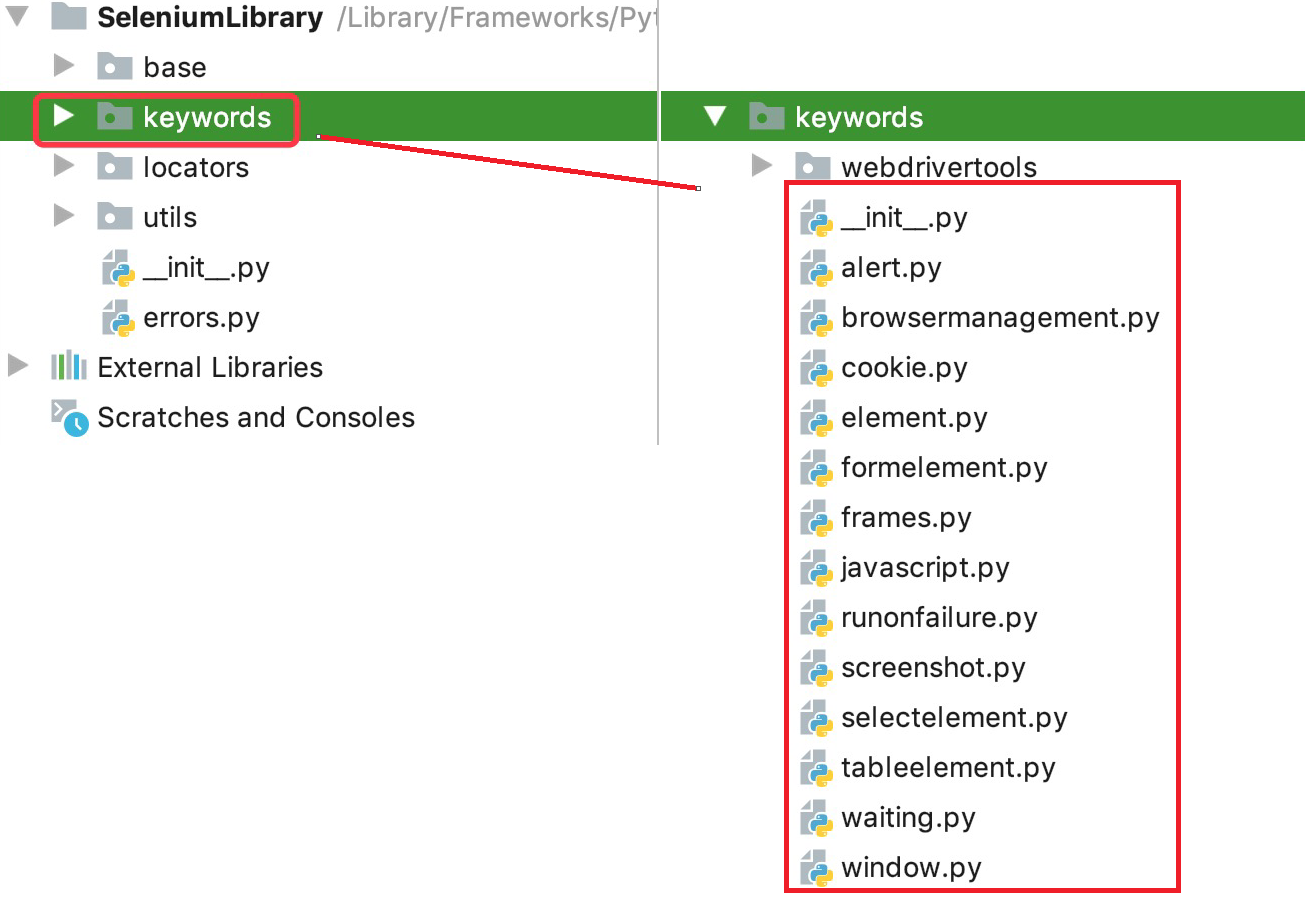
SeleniumLibrary是一个python第三方库(存放在python安装目录下的Lib/site-packages/SeleniumLibrary)。它的结构如下,其中keywords目录下存放的是关键字。
在源码中,是分门别类的来存放关键字。包括alert弹框、表格/select/iframe等元素操作、等待、窗口等。
SeleniumLibrary的源代码中,很多地方都直接使用了selenium的API来封装网页的操作,可以说是在selenium之上,封装了更多的元素操作关键字,提供给robot框架的使用者。毕竟有现成的“轮子”,就没有必要再重新造了。
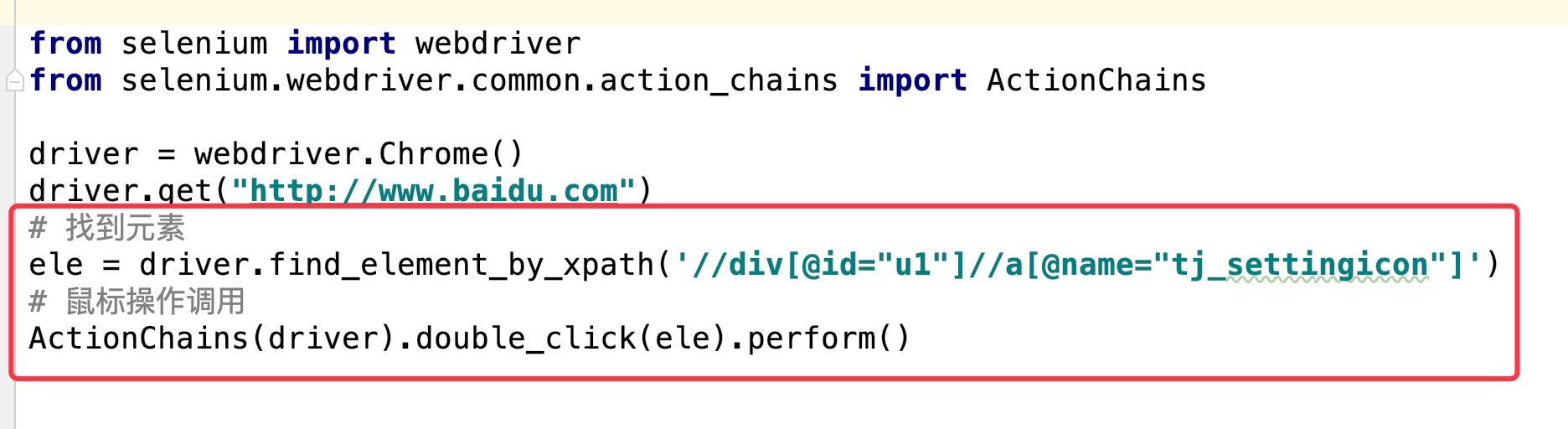
比如上图中elment.py当中的鼠标操作。在selenium当中,ActionChains类是用来专门实现鼠标操作的。
以元素双击操作为例,如果使用python+selenium库来实现双击操作,需要以下代码:
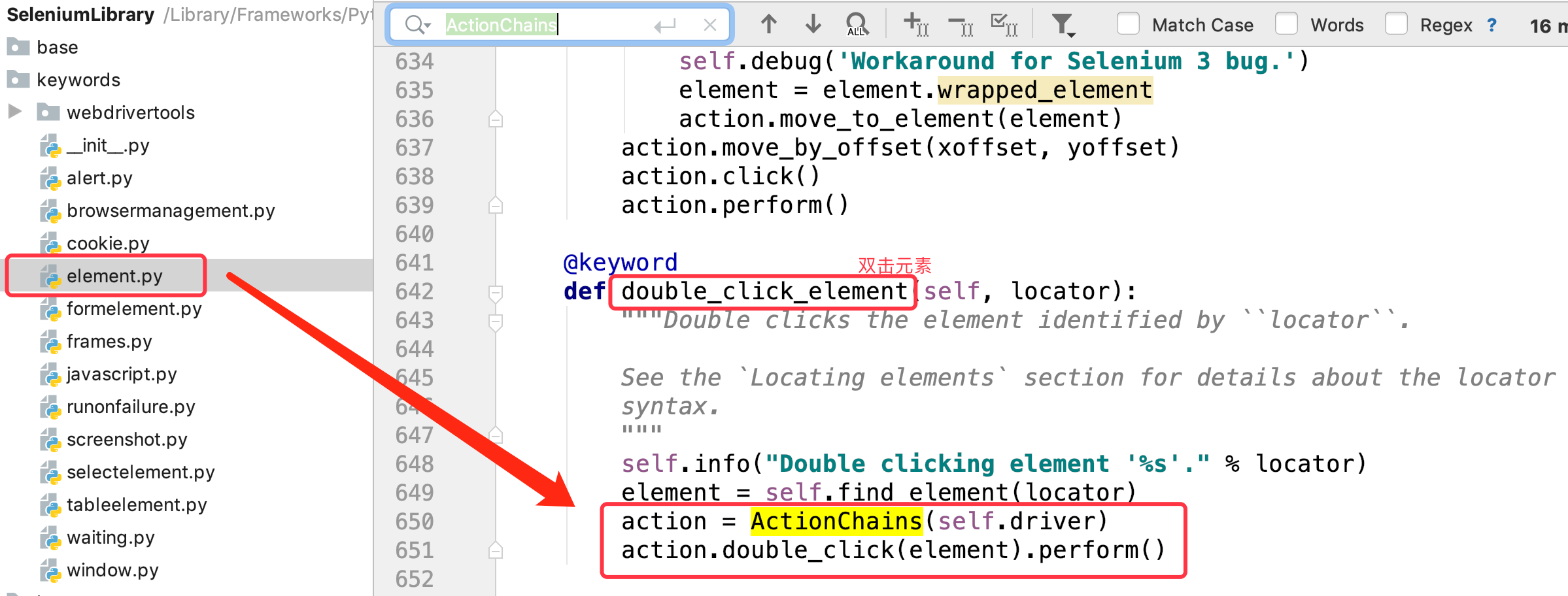
在SeleniumLibrary当中,关键字**double click element** 就将元素和鼠标双击操作封装在一起。只要传入元素定位即可(如下图所示)。
3、SeleniumLibrary关键字分类解读
1) 引入SeleniunLibrary库时,初始化参数
SeleniumLibrary在robotframework当中,引入时会将SeleniumLibrary这个类初始化。
初始化的参数是对所有关键字生效的。

**Timeout:**等待超时时间。关键字当中有timeout参数的,都使用此处的默认值,5秒。
Implicit wait: 隐性等待时长。0.0表示没有隐性等待。
run on failure: 关键字运行失败时的动作。Capture Page Screenshot是截取页面图片的关键字。表示运行失败时,自动截取当前网页图片, 即失败时自动截图功能。
Screenshot root directory: 截取的网页图片存放路径 。None表示不指定路径 ,默认与输出文件同目录。
我们在robot当中引入SeleniumLibrary时,可以修改默认参数值。比如修改默认timeout为15s

2)元素定位语法:
在web自动化当中,有8大定位方式。无论用什么样的语言/框架,定位方式都是通用的。
在robot框架当中,定位语法有以下2种表达方式:
- 定位策略:定位表达式(比如 id:kw)
- 定位策略=定位表达式(比如 id=kw)
在robot当中,除了8大定位方式以外,还额外扩展了几种,整体的定位方式如下(摘抄自官方文档):
| 定位策略 | 匹配方式 | 定位示例 |
|---|---|---|
| id | 元素的id属性 | id:example |
| name | 元素的name属性 | name:example |
| identifier | 元素的id或者name属性 | identifier:example |
| class | 元素的class属性 | class:example |
| tag | 元素的标签名称 | tag:div |
| xpath | xpath定位表达式 | xpath://div[@id="example"] |
| css | css selector定位表达式 | css:div#example |
| dom | DOM表达式 | dom:document.images[5] |
| link | 精确匹配链接元素的文本内容 | link:The example |
| partial link | 部分匹配链接元素的文本内容 | partial link:he ex |
| jquery | jQuery表达式 | jquery:div.example |
示例:
| Click Element | id:foo | 点击id为foo的元素。 |
|---|---|---|
| Click Element | css:div#foo h1 | 点击 id为foo的div元素后代当中的h1元素 |
| Click Element | xpath=//div[@id="foo"]//h1 | 同上一个。 |
| Click Element | //*[contains(text(), "example")] | 点击 文本内容包含example的元素 |
注意:xpath定位表达式可省略前缀:xpath。
#### 3)浏览器和窗口操作关键字
| 关键字名称 | 关键字说明 |
|---|---|
| open browser | 打开浏览器并访问系统地址。url:网站地址,browser:浏览器类型。 |
| close browser | 关闭浏览器。 |
| maximize browser window | 当前窗口最大化。 |
| get window size | 获取当前窗口的大小 |
| set window size | 设置窗口大小。 |
| get window handles | 获取浏览器中,所有窗口的句柄。 |
| switch window | 切换窗口。可根据窗口的句柄、标题、名称等切换。 |
| get window names | 获取浏览器,所有窗口的名称。 |
| get window titles | 获取所有窗口的标题。 |
| get locations | 获取所有窗口的url。 |
#### 4)元素通用操作关键字(包含鼠标/键盘操作):
| 关键字名称 | 关键字说明 |
|---|---|
| click ement | 点击元素。 |
| input text | 在元素中输入文本值。 |
| get element attribute | 获取元素的某一个属性值。 |
| get element size | 获取元素的大小。 |
| get value | 获取元素的value属性值。 |
| get text | 获取元素的文本内容 |
| clear element text | 清除元素的文本值。 |
| get webelement | 获取一个元素对象。WebElment对象。 |
| get webelements | 获取匹配的所有元素对象。WebElment对象。 |
| set focus to element | 元素获取焦点。 |
| double click element | 双击元素 |
| scroll element into view | 滚动元素到可见区域 |
| drag and drop | 将一个元素拖拽到另一个元素区域中。 |
| mouse over | 鼠标悬浮在元素上 |
| press keys | 键盘按键操作。 |
5)select/frame/alert/表格等操作关键字:
| 关键字名称 | 关键字说明 |
|---|---|
| get list items | select/option元素中,获取所有的options选项。 |
| select from list by index | select/option元素中,根据下标来选择option选项 |
| select from list by value | select/option元素中,根据value属性来选择option选项 |
| select from list by label | select/option元素中,根据文本内容来选择option选项 |
| select frame | 切换到指定的iframe当中。 |
| unselect frame | 退出iframe,切换到默认的html页面中。 |
| handle alert | 关闭alert弹出框。 |
| input text into alert | 输入文本到alert弹框中,并关闭alert弹出框。 |
| choose file | 在上传文件的输入框中(input元素的type为file)输入文本地址。 |
| get table cell | 获取表格的单元格值。行号和列号起始值为1.包含表头和表尾所对应的行。 |
#### 6)元素等待关键字
(关键字中包含wait的, timeout参数默认为seleniumlibrary初始化值,默认为5秒):
| 关键字名称 | 关键字说明 |
|---|---|
| wait for condition | 等待条件成立:条件为js表达式,表达式的结果要为布尔值。 |
| wait until element is visible | 等待指定的元素可见 |
| wait until element is not visible | 等待指定的元素不可见 |
| wait until element is enabled | 等待指定的元素可用 |
| wait until element contains | 等待指定的元素 包含 指定的文本内容 |
| wait until element does not contain | 等待指定的元素 不包含 指定的文本内容 |
| wait until page contains element | 等待页面 包含指定的元素 |
| wait until page contains element | 等待页面 不包含指定的元素 |
| wait until page contains | 等待页面 包含指定的文本内容 |
| wait until page does not contain | 等待页面 不包含指定的文本内容 |
7)断言关键字(关键字中包含should的均是):
| 关键字名称 | 关键字说明 |
|---|---|
| page should contain element | 页面应当 包含指定的元素 |
| page should not contain element | 页面应当 不包含指定的元素 |
| locator should match x times | 元素定位表达式应该匹配 指定 次数 |
| element should be visible | 指定的元素 应当可见 |
| element should not be visible | 指定的元素 应当不可见 |
| element should be enabled | 指定的元素 应当可用 |
| element should be disabled | 指定的元素 应当不可用 |
| element text should be | 指定元素的文本内容 应当是 指定内容 |
| element text should not be | 指定元素的文本内容 应当不是 指定内容 |
| element should be focused | 指定的元素 应当为焦点状态 |
还有很多其它断言的关键字,不一一列举。
8)截屏类关键字:
| 关键字名称 | 关键字说明 |
|---|---|
| capture page screenshot | 截取当前页面图片。 |
| capture element screenshot | 截取指定元素的图片。 |
| set screenshot directory | 设置截图存储目录。 |
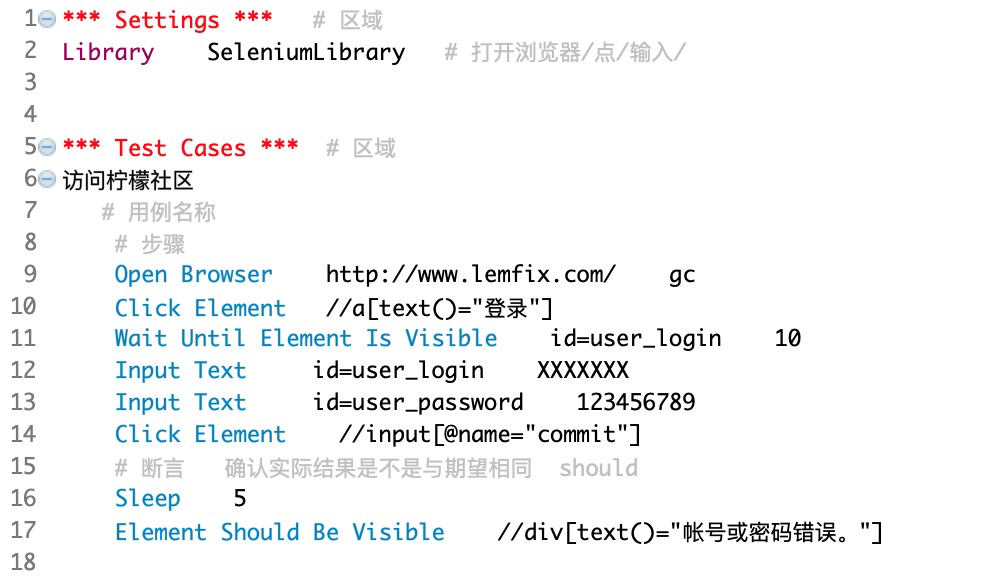
4、robot - web自动化使用示例
欢迎来到testingpai.com!
注册 关于