正则表达式
一、概述
1. 概念
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
2. 目的
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
-
a. 给定的字符串是否符合正则表达式的过滤逻辑(称作“匹配”);
例如:邮箱匹配,电话号码匹配
-
b. 可以通过正则表达式,从字符串中获取我们想要的特定部分。
爬虫中解析html数据
3. 特点:
- a. 灵活性、逻辑性和功能性非常的强;
- b. 可以迅速地用极简单的方式达到字符串的复杂控制。
- c. 对于刚接触的人来说,比较晦涩难懂。
4. 学习方法
- a. 做好笔记,不要死记硬背
- b. 大量练习
python中通过系统库 re 实现正则表达式的所有功能
二、正则表达式符号
1. 普通字符
下面的案例使用re模块的findall()函数,函数参考如下:
re.findall(pattern, string, flag)- 在字符串中找到正则表达式所匹配的所有子串,并返回列表,如果没有找到返回空列表
pattern: 正则表达式string:被匹配的字符串- flag:标志位用来控制正则表达式匹配方式
在最简单的情况下,一个正则表达式看上去就是一个普通的查找串
import re
s1 = "testing123"
s2 = "Testing123"
r = re.findall("test", s1) # 表示在s1中找到字符串"test"
print(r)
运行结果:
['test']
r = re.findall("test", s2)
print(r)
运行结果:
[]
r = re.findall("test", s2, re.I) # 修饰符re.I:使匹配对大小写不敏感
print(r)
运行结果:
['Test']
2. 元字符
. ^ $ * + ? { } [ ] | ( ) \
2.1 通配符.
匹配除\n之外的任何单个字符
s1 = "testing123"
s2 = "testing123\n"
r = re.findall(".", s1)
print(r)
运行结果:
['t', 'e', 's', 't', 'i', 'n', 'g', '1', '2', '3']
r = re.findall(".", s2) # 除“\n”
print(r)
运行结果:
['t', 'e', 's', 't', 'i', 'n', 'g', '1', '2', '3']
修饰符re.S使.匹配包括换行在内的所有字符
r = re.findall(".", s2, re.S)
print(r)
运行结果:
['t', 'e', 's', 't', 'i', 'n', 'g', '1', '2', '3', '\n']
2.2 脱字符^
匹配输入字符串的开始位置
s1 = "testing\nTesting\ntest"
r = re.findall("^test", s1) # 默认只匹配单行
print(r)
运行结果:
['test']
r = re.findall("^test", s1, re.M) # 修饰符re.M:多行匹配
print(r)
运行结果:
['test', 'test']
r = re.findall("^test", s1, re.I | re.M)
print(r) # 输出['test', 'Test', 'test']
运行结果:
['test', 'Test', 'test']
2.3 美元符$
匹配输入字符串的结束位置
s1 = "testing\nTesting\ntest"
r = re.findall("testing$", s1) # 默认匹配单行
print(r)
运行结果:
[]
r = re.findall("testing$", s1, re.M) # 修饰符re.M:多行匹配
print(r) # 输出['testing']
运行结果:
['testing']
r = re.findall("testing$", s1, re.I | re.M) # 多个修饰符通过 OR(|) 来指定
print(r) # 输出['testing', 'Testing']
运行结果:
['testing', 'Testing']
2.4 重复元字符*,+,?
*匹配前面的子表达式任意次+匹配前面的子表达式一次或多次(至少一次)?匹配前面的子表达式0次或1次
s1 = "z\nzo\nzoo"
r = re.findall("zo*", s1) # 匹配o{0,}
print(r)
运行结果:
['z', 'zo', 'zoo']
r = re.findall("zo+", s1) # 匹配o{1,}
print(r)
运行结果:
['zo', 'zoo']
r = re.findall("zo?", s1) # 匹配o{0,1}
print(r)
运行结果:
['z', 'zo', 'zo']
2.5 重复元字符{}
也是控制匹配前面的子表达式次数
s1 = "z\nzo\nzoo"
r = re.findall("zo*", s1) # 匹配o{0,},逗号后不能空格
r1 = re.findall(r"zo{0,}", s1)
print(r) # ['z', 'zo', 'zoo']
print(r1) # ['z', 'zo', 'zoo']
运行结果:
['z', 'zo', 'zoo']
['z', 'zo', 'zoo']
r = re.findall("zo+", s1) # 匹配o{1,}
r1 = re.findall(r"zo{1,}", s1)
print(r) # 输出['zo', 'zoo']
print(r1) # 输出['zo', 'zoo']
运行结果:
['zo', 'zoo']
['zo', 'zoo']
r1 = re.findall("zo{2}", s1) # 匹配o{0,1}
print(r1) # 输出['zoo']
运行结果:
['zoo']
2. 6 字符组[]
表示匹配给出的任意字符
s1 = "test\nTesting\nzoo"
r = re.findall("[eio]", s1) # 匹配包含的任意字符
print(r)
运行结果:
['e', 'e', 'i', 'o', 'o']
r = re.findall("[e-o]", s1) # 匹配包含的字符范围
print(r)
运行结果:
['e', 'e', 'i', 'n', 'g', 'o', 'o']
r = re.findall("^[eio]", s1, re.M) # 回忆脱字符,匹配以[eio]开头字符。
print(r)
运行结果:
[]
r = re.findall("[^eio]", s1) # 匹配未包含的任意字符
print(r)
运行结果:
['t', 's', 't', '\n', 'T', 's', 't', 'n', 'g', '\n', 'z']
r1 = re.findall("[^e-o]", s1) # 匹配未包含的字符范围
print(r1) # 输出['t', 's', 't', '\n', 'T', 's', 't', '\n', 'z']
['t', 's', 't', '\n', 'T', 's', 't', '\n', 'z']
2.7 选择元字符|
表示两个表达式选择一个匹配
s1 = "z\nzood\nfood"
r = re.findall("z|food", s1) # 匹配"z"或"food"
print(r)
运行结果:
['z', 'z', 'food']
r = re.findall("[z|f]ood", s1) # 匹配"zood"或"food"
print(r) #
运行结果:
['zood', 'food']
2.8 分组元字符()
将括号之间的表达式定义为组(group),并且将匹配这个子表达式的字符返回
s1 = "z\nzood\nfood"
r = re.findall("[z|f]o*", s1) # 不加分组,拿到的引号内正则表达式匹配到的字符
print(r)
运行结果:
['z', 'zoo', 'foo']
r = re.findall("[z|f](o*)", s1) # 加上分组,返回的将是引号内正则表达式匹配到的字符中()中的内容。
print(r) # ['', 'oo', 'oo']
运行结果:
['', 'oo', 'oo']
2.9 转义元字符\
用来匹配元字符本身时的转义,和特定字符组成字符串,见预定义字符组
s = '12345@qq.com'
r = re.findall('\.', s)
print(r)
运行结果:
['.']
2.10 非贪婪模式
在默认情况下,元字符*,+和{n,m}会尽可能多的匹配前面的子表达式,这叫贪婪模式。
s = "abcadcaec"
r = re.findall(r"ab.*c", s) # 贪婪模式,尽可能多的匹配字符(.*或者.+)
print(r)
运行结果:
['abcadcaec']
r = re.findall(r"ab.*?c", s) # 非贪婪模式,尽可能少的匹配字符
print(r)
运行结果:
['abc']
r = re.findall('ab.+c', s) # 贪婪
print(r)
运行结果:
['abcadcaec']
r = re.findall('ab.+?c', s) # 非贪婪
print(r)
运行结果:
['abcadc']
r = re.findall('ab.{0,}', s) # 贪婪
print(r)
运行结果:
['abcadcaec']
r = re.findall('ab.{0,}?', s) # 非贪婪
print(r)
运行结果:
['ab']
3. 预定义字符组
元字符\与某些字符组合在一起表示特定的匹配含义
3.1 \d
匹配单个数字,等价于[0-9]
s = "<a href=' asdf'>1360942725</a>"
a = re.findall('\d', s)
print(a)
运行结果:
['1', '3', '6', '0', '9', '4', '2', '7', '2', '5']
a = re.findall('\d+', s)
print(a)
运行结果:
['1360942725']
3.2 \D
匹配任意单个非数字字符,等价于[^0-9]
a = re.findall('\D', s)
print(a)
运行结果:
['<', 'a', ' ', 'h', 'r', 'e', 'f', '=', "'", ' ', 'a', 's', 'd', 'f', "'", '>', '<', '/', 'a', '>']
3.3\s
匹配任意单个空白符,包括空格,制表符(tab),换行符等
s = 'fdfa**68687+ 我怕n fdg\tf_d\n'
a = re.findall('\s', s)
print(a)
运行结果:
[' ', ' ', '\t', '\n']
3.4 \S
匹配任何非空白字符
s = 'fdfa**68687+ 我怕n fdg\tf_d\n'
a = re.findall('\S', s)
print(a)
运行结果:
['f', 'd', 'f', 'a', '', '', '6', '8', '6', '8', '7', '+', '我', '怕', 'n', 'f', 'd', 'g', 'f', '_', 'd']
3.5 \w
匹配除符号外的单个字母,数字,下划线或汉字等
a = re.findall("\w", s)
print(a)
运行结果:
['f', 'd', 'f', 'a', '6', '8', '6', '8', '7', '我', '怕', 'n', 'f', 'd', 'g', 'f', '_', 'd']
小案例
- 检测邮箱
s = "3003756995@qq.com"
a = re.findall('^\w+@\w+\.com$', s) # 检测邮箱
if a:
print('是正确格式的邮箱')
else:
print('不是邮箱地址')
是正确格式的邮箱
2. 检测手机号码
s = '13812345678'
r = re.findall('^1[3-9]\d{9}$', s) # 检查手机号码
if r:
print('手机号码格式正确')
else:
print('手机号码格式不正确')
手机号码格式正确
4.re模块常用函数
4.1 re.match
re.match(pattern, string, flag)- 尝试从字符串的起始位置匹配一个模式,成功返回匹配对象,否则返回None
pattern: 正则表达式string: 被匹配的字符串flag: 标志位,表示匹配模式
import re
url = 'www.hhxpython.com'
res = re.match('www', url) # 'www' 就是正则表达式,没有元字符表示匹配字符本身
# re.match默认是从字符串开头匹配,等价于'^www'
print(res)
运行结果:
<re.Match object; span=(0, 3), match='www'>
res2 = re.match('hhx', url)
print(res2)
运行结果:
None
匹配对象
match函数返回一个匹配对象,通过这个对象可以取出匹配到的字符串和分组字符串
line = 'Good good study, Day day up!'
match_obj = re.match('(?P<aa>.*), (.*) (.*)', line)
if match_obj:
print(match_obj.group()) # 返回匹配到的字符串
print(match_obj.group(1)) # 返回对应序号分组字符串 从1开始
print(match_obj.group(2))
print(match_obj.group(3))
else:
print('not found')
print(match_obj.groups()) # 返回分组字符串元组
print(match_obj.groupdict()) # 按照分组名和分组字符串组成字典 (?P<name>pattern)
运行结果:
Good good study, Day day up!
Good good study
Day day
up!
('Good good study', 'Day day', 'up!')
{'aa': 'Good good study'}
4.2 re.search
re.search(pattern, string, flag)- 扫描整个字符串返回第一个成功的匹配对象
pattern: 正则表达式string: 被匹配的字符串flag: 标志位,表示匹配模式
url = 'www.hhxpython.com'
res = re.search('www', url) # 'www' 就是正则表达式,没有元字符表示匹配字符本身
print(res)
运行结果:
<re.Match object; span=(0, 3), match='www'>
res2 = re.search('hhx', url)
print(res2)
运行结果:
<re.Match object; span=(4, 7), match='hhx'>
res3 = re.search('h', url)
print(res3)
运行结果:
<re.Match object; span=(4, 5), match='h'>
4.3 re.sub
re.sub(pattern, repl, string, count=0, flag)- 将表达式匹配到的部分替换为制定字符串,返回替换后的新字符串
pattern: 正则表达式repl: 用来替换的字符串string: 被匹配的字符串count: 替换次数,默认为0,表示全部替换flags: 标志位,表示匹配模式
phone = '2004-959-559 # 这是一个国外电话号码'
# 删除字符串中的python注释
num = re.sub('#.*', '', phone)
print(num)
运行结果:
2004-959-559
# 删除连接符号 -
num = re.sub('-', '', num)
print(num)
运行结果:
2004959559
4.4 re.findall
re.findall(pattern, string, flags=0)- 在字符串中找到正则表达式匹配的所有子串,返回一个列表,匹配失败则返回空列表
pattern: 正则表达式string: 被匹配的字符串flags: 标志位,表示匹配模式
res1 = re.findall('day', line, re.I)
res2 = re.search('day', line, re.I)
res3 = re.match('day', line, re.I)
print('findall', res1)
print('search', res2.group())
print('search', res3)
运行结果:
findall ['Day', 'day']
search Day
search None
match,search,findall的区别
match从头开始匹配,成功返回匹配对象,失败返回Nonesearch只匹配第一个,成功返回匹配对象,失败返回Nonefindall匹配所有,成功返回所有匹配到的字符串组成的列表,失败返回空列表
4.5 re.compile
re.compile(pattern, [flags])- compile函数用于编译正则表达式,生成一个正则表达式对象,该对象调用findall,search,match,sub 等方法
pattern: 正则表达式flags: 标志位,表示匹配模式
面向对象编程时使用
pattern = re.compile('day', re.I)
res1 = pattern.findall(line)
res2 = pattern.search(line)
res3 = pattern.match(line)
print('findall', res1)
print('search', res2.group())
print('match', res3)
运行结果:
findall ['Day', 'day']
search Day
match None
三、应用场景
在做自动化测试时用例数据是动态的,需要程序自动处理。
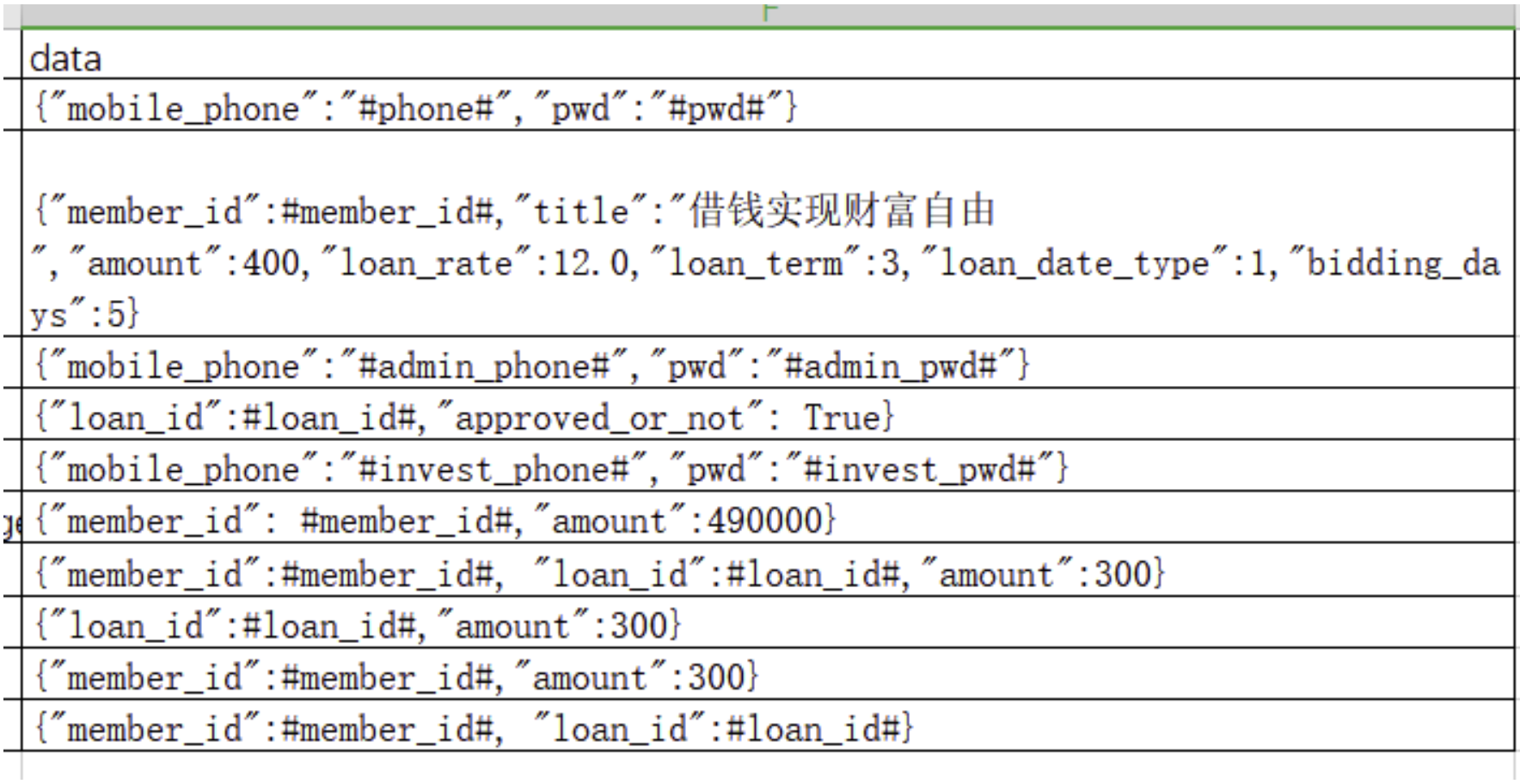
import re
# 用例json数据字符串
data = '{"member_id":"#member_id#","pwd":"#pwd#","user":"#user#","loan_id":"#loan#"}'
# 动态数据
class DynamicData:
member_id = 123
user = "musen"
pwd = "lemonban"
loan = 31
def mk_data(json_str,dn_data):
while True:
item = re.search('#(.*?)#', json_str)
# 没有匹配到说明匹配完成
if not item:
break
# 需要被替换的字符串
need_replace = item.group()
# 需要被替换的参数名
key = item.group(1)
# 替换
json_str = json_str.replace(need_replace, str(getattr(dn_data, key)))
return json_str
mk_data(data, DynamicData)
运行结果:
'{"member_id":"123","pwd":"lemonban","user":"musen","loan_id":"31"}'
欢迎来到testingpai.com!
注册 关于