一、序列类型
序列类型用来表示有序的元素集合。
1. 字符串
python中字符串用str表示,字符串是使用单引号,双引号,三引号包裹起来的字符的序列,用来表示文本信息。
1.1 字符串的定义
a = 'a'
b = "bc"
c = """hello,world"""
d = '''hello,d'''
e = """
hello,
world!
"""
print('a的类型为:', type(a)) # a的类型为: <class 'str'>
print('b的类型为:', type(b)) # b的类型为: <class 'str'>
print('c的类型为:', type(c)) # c的类型为: <class 'str'>
print('d的类型为:', type(d)) # d的类型为: <class 'str'>
print('e的类型为:', type(e)) # e的类型为: <class 'str'>
a的类型为: <class 'str'>
b的类型为: <class 'str'>
c的类型为: <class 'str'>
d的类型为: <class 'str'>
e的类型为: <class 'str'>
使用单引号和双引号进行字符串定义没有任何区别,当要表示字符串的单引号时用双引号进行定义字符串,反之亦然。
一对单引号或双引号只能创建单行字符串,三引号可以创建多行表示的字符串。三双引号一般用来做多行注释,表示函数,类定义时的说明。
print('最近我看了"平凡的世界"')
print("最近我看了'平凡的世界'")
最近我看了"平凡的世界"
最近我看了'平凡的世界'
定义空字符串
a = ''
print(a)
1.2 字符串的索引
任何序列类型中的元素都有 索引用来表示它在序列中的位置。
字符串是字符的序列表示,单个字符在字符串中的位置使用 索引来表示,也叫下标。
索引使用整数来表示。
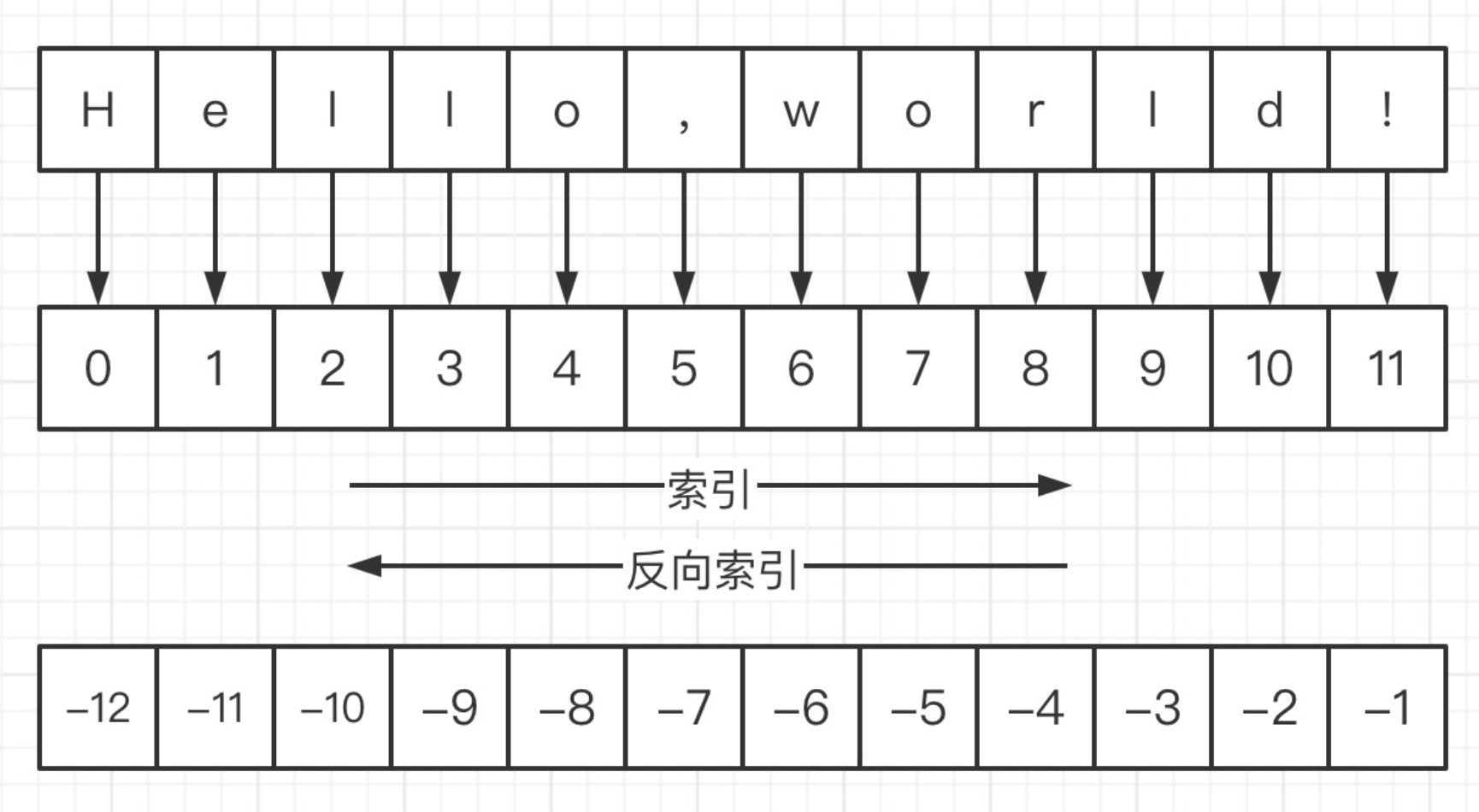
通过 索引可以获取字符串中的单个字符
语法如下:
str[index]
s = 'hello world!'
print(s[0])
print(s[-1])
h
!
注意字符串索引从0开始
1.3 字符串的切片
获取序列中的子序列叫切片。
字符串的切片就是获取字符串的子串。
字符串切片的语法如下:
str[start:end:step]
start表示起始索引,end表示结束索引,step表示步长。
str[m:n:t]表示从字符串索引为 m到 n之间不包含 n每隔 t个字符进行切片。
当 step为1的时候可以省略。
特别的,当 step为负数时,表示反向切片。
s = '0123456789'
print(s[1:5]) # 包头不包尾
1234
print(s[:5]) # 从头开始切可以省略start
01234
print(s[1:]) # 切到末尾省略end
123456789
print(s[1::2]) # 步长为2进行切片
13579
print(s[1::-2]) # 步长为负数反向切片
1
思考
获取一个字符串的逆串,例如 'abc'的逆串是 'cba'。
1.4 字符串拼接
python中可以通过 +拼接两个字符串
a = 'hello'
b = ' '
c = 'world!'
print(a+b+c)
hello world!
字符串和整数进行乘法运算表示重复拼接这个字符串
print('*' * 10)
1.5 字符串常用方法
通过内建函数 dir可以返回传入其中的对象的所有方法名列表。
print(dir(str))
['add', 'class', 'contains', 'delattr', 'dir', 'doc', 'eq', 'format', 'ge', 'getattribute', 'getitem', 'getnewargs', 'gt', 'hash', 'init', 'init_subclass', 'iter', 'le', 'len', 'lt', 'mod', 'mul', 'ne', 'new', 'reduce', 'reduce_ex', 'repr', 'rmod', 'rmul', 'setattr', 'sizeof', 'str', 'subclasshook', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isascii', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
通过内建函数help可以返回传入函数的帮助信息。
help('abc'.replace)
Help on built-in function replace:
replace(old, new, count=-1, /) method of builtins.str instance
Return a copy with all occurrences of substring old replaced by new.
count
Maximum number of occurrences to replace.
-1 (the default value) means replace all occurrences.
If the optional argument count is given, only the first count occurrences are
replaced.
官方文档地址
1.6 字符串和数值的相互转化
1 和 '1'不同,1.2和 '1.2'也不相同,但是它们可以相互转化
# 整数和字符串之间的转化
int('1')
1
str(1)
'1'
# 浮点数和字符串之间的转化
float('1.2')
1.2
str(1.2)
'1.2'
# 尝试 int('1.2')看看结果会是什么
int('1.2')
1.7 转义符
在需要在字符中使用特殊字符时,python 用反斜杠 \ 转义字符。常用转义字符如下表:
| (在行尾时) | 续行符 |
|---|---|
\\ |
反斜杠符号 |
\' |
单引号 |
\" |
双引号 |
| \a | 响铃 |
| \n | 换行 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
print('窗前明月光,\n疑是地上霜。') # 输出换行
窗前明月光,
疑是地上霜。
print('对\\错') # 输出反斜杠本身
对\错
print('\'') # 输出单引号本身
'
1.8 字符串格式化
在实际工作中经常需要动态输出字符。
例如,我们通过程序计算计算机的内存利用率,然后输出
10:15 计算机的内存利用率为30%
其中下划线内容会动态调整,需要根据程序执行结果进行填充,最终形成上述格式的字符串输出。
python支持两种形式的字符串格式化
% 字符串格式化
语法格式如下:
%[(name)][flags][width][.precision]typecode
(name)可选,用于选择指定的keyflags可选,可供选择的值有,注意只有在和数值类型的typecode配合才起作用+, 右对齐,正数前加正号,负数前加负号-, 左对齐,正数前无符号,负数前加负号空格, 右对齐,正数前加空格,负数前加负号0, 右对齐,正数前无符号,复数前加负号;用0填充空白处
width,可选字符串输出宽度.precision可选,小数点后保留位数,注意只有在和数值类型的typecode配合才起作用typecode必选s,获取传入对象的字符串形式,并将其格式化到指定位置r,获取传入对象的__repr__方法的返回值,并将其格式化到指定位置c,整数:将数字转换成其unicode对应的值,10进制范围为 0 <= i <= 1114111(py27则只支持0-255);字符:将字符添加到指定位置o,将整数转换成 八 进制表示,并将其格式化到指定位置x,将整数转换成十六进制表示,并将其格式化到指定位置d,将整数、浮点数转换成 十 进制表示,并将其格式化到指定位置e,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(小写e)E,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(大写E)f, 将整数、浮点数转换成浮点数表示,并将其格式化到指定位置(默认保留小数点后6位)F,同上g,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是e;)`G,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是E;)`- %,当字符串中存在格式化标志时,需要用 %%表示一个百分号
res = '%s计算机的内存利用率为%s%%' % ('11:15', 75)
print(res)
# '%s'作为槽位和 % 号后提供的值按顺序一一对应
11:15计算机的内存利用率为75%
res = '%(time)s计算机的内存利用率为%(percent)s%%' % {'time':'11:15', 'percent': 75}
# % 后是字典时,可以通过name指定key对应的值
print(res)
11:15计算机的内存利用率为75%
# 输出两位数的月份,例如01,02
res = '%02d' % 8
print(res)
08
# 保留2为小数
res = '%(time)s计算机的内存利用率为%(percent).2f%%' % {'time':'11:15', 'percent': 75.123}
print(res)
11:15计算机的内存利用率为75.12%
print('字符串%(key)s,十进制%(key)d,科学计数%(key)e,八进制%(key)o,16进制%(key)x,unicode字符%(key)c' % {'key': 65})
字符串65,十进制65,科学计数6.500000e+01,八进制101,16进制41,unicode字符A
format函数格式化
%的字符串格式化继承自C语言,python中给字符串对象提供了一个 format函数进行字符串格式化,且功能更强大,并且大力推荐,所以我们要首选使用。
基本语法是:
<模板字符串>.format(<逗号分隔的参数>)
在模板字符串中使用 {}代替以前的 %作为槽位
'{}计算机的内存利用率为{}%'.format('11:15', 75)
'11:15计算机的内存利用率为75%'
当format中的参数使用位置参数提供时,{}中可以填写参数的整数索引和参数一一对应
'{0}计算机的内存利用率为{1}%'.format('11:15', 75)
'11:15计算机的内存利用率为75%'
当format中的参数使用关键字参数提供时,{}中可以填写参数名和参数一一对应
'{time}计算机的内存利用率为{percent}%'.format(time='11:15', percent=75)
'11:15计算机的内存利用率为75%'
{}中除了可以写参数索引外,还可以填写控制信息来实现更多的格式化功能,语法如下
{<参数序号>:<格式控制标记>}
其中格式控制标记格式如下
[fill][align][sign][#][0][width][,][.precision][type]
- fill 【可选】空白处填充的字符
- align 【可选】对齐方式(需配合width使用)
-
- <,内容左对齐
- >,内容右对齐(默认)
- =,内容右对齐,将符号放置在填充字符的左侧,且只对数字类型有效。 即使:符号+填充物+数字
- ^,内容居中
- sign 【可选】有无符号数字
- +,正号加正,负号加负;
- -,正号不变,负号加负;
- 空格 ,正号空格,负号加负;
- #
【可选】对于二进制、八进制、十六进制,如果加上#,会显示 0b/0o/0x,否则不显示 - , 【可选】为数字添加分隔符,如:1,000,000
- width 【可选】格式化位所占宽度
- .precision 【可选】小数位保留精度
- type 【可选】格式化类型
- 传入” 字符串类型 “的参数
- s,格式化字符串类型数据
- 空白,未指定类型,则默认是None,同s
- 传入“ 整数类型 ”的参数
- b,将10进制整数自动转换成2进制表示然后格式化
- c,将10进制整数自动转换为其对应的unicode字符
- d,十进制整数
- o,将10进制整数自动转换成8进制表示然后格式化;
- x,将10进制整数自动转换成16进制表示然后格式化(小写x)
- X,将10进制整数自动转换成16进制表示然后格式化(大写X)
- 传入“ 浮点型或小数类型 ”的参数
- e, 转换为科学计数法(小写e)表示,然后格式化;
- E, 转换为科学计数法(大写E)表示,然后格式化;
- f , 转换为浮点型(默认小数点后保留6位)表示,然后格式化;
- F, 转换为浮点型(默认小数点后保留6位)表示,然后格式化;
- g, 自动在e和f中切换
- G, 自动在E和F中切换
- %,显示百分比(默认显示小数点后6位)
- 传入” 字符串类型 “的参数
# 输出两位数的月份,例如01,02
res = '{:0>2}'.format(8)
print(res)
08
# 保留2为小数
res = '{time}计算机的内存利用率为{percent:.2%}'.format(time='11:15', percent=0.75123)
print(res)
11:15计算机的内存利用率为75.12%
print('字符串{key},十进制{key:d},科学计数{key:e},八进制{key:o},16进制{key:x},unicode字符{key:c}'.format(key=65))
字符串65,十进制65,科学计数6.500000e+01,八进制101,16进制41,unicode字符A
格式字符串字面值
3.6新版功能:
格式字符串字面值或称为 f-string是标注了 'f' 或 'F' 前缀的字符串字面值。这种字符串可包含替换字段,即以 {} 标注的表达式。
基本语法是:
literal_char{expression[:format_spec]}
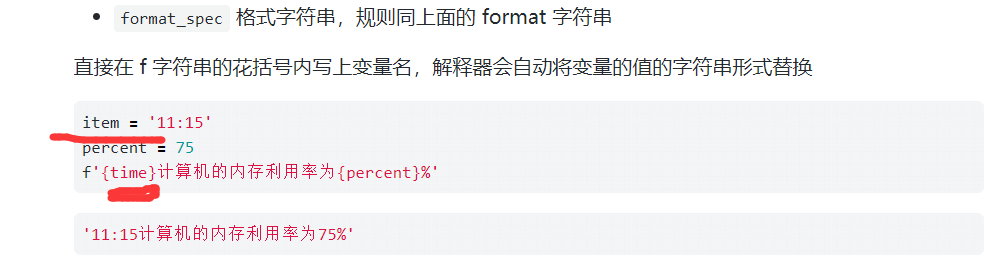
literal_char普通字符expression表达式,变量或函数。。format_spec格式字符串,规则同上面的format字符串
直接在f字符串的花括号内写上变量名,解释器会自动将变量的值的字符串形式替换
item = '11:15'
percent = 75
f'{time}计算机的内存利用率为{percent}%'
'11:15计算机的内存利用率为75%'
带格式的f字符串
# 输出两位数的月份,例如01,02
month = 8
res = f'{month:0>2}'
print(res)
08
# 保留2为小数
time = '11:15'
percent = 0.75123
res = f'{time}计算机的内存利用率为{percent:.2%}'
print(res)
11:15计算机的内存利用率为75.12%
key = 65
print(f'字符串{key},十进制{key:d},科学计数{key:e},八进制{key:#o},16进制{key:x},unicode字符{key:c}')
字符串65,十进制65,科学计数6.500000e+01,八进制0o101,16进制41,unicode字符A
包含运算和函数的f字符串
num = -1
print(f'{num+1=}')
num+1=0
print(f'{abs(num)=}')
abs(num)=1
s = 'abcd'
print(f'{s[:python :-1]=}')
s[::-1]='dcba'
2. 列表
python中列表(list)用来表示任意元素的序列,元素可以是任意数据类型,序列中的元素可以增,删,改。
2.1 列表的定义
列表由一对中括号进行定义,元素与元素直接使用逗号隔开。
a = [] # 空列表
b = ["a", "b", "cde"] # 字符串列表项
c = [1, "b", "c"] # 数字列表项
d = [1, "b", []] # 列表列表项
e = [1, "b", [2, "c"]] # 列表作为列表的元素叫做列表的嵌套
print('a的类型为:', type(a)) # a的类型为: <class 'list'>
print('b的类型为:', type(b)) # b的类型为: <class 'list'>
print('c的类型为:', type(c)) # c的类型为: <class 'list'>
print('d的类型为:', type(d)) # d的类型为: <class 'list'>
print('e的类型为:', type(e)) # e的类型为: <class 'list'>
a的类型为: <class 'list'>
b的类型为: <class 'list'>
c的类型为: <class 'list'>
d的类型为: <class 'list'>
e的类型为: <class 'list'>
2.2 列表的拼接
像字符串一样,列表之间可以进行加法运算实现列表的拼接,列表可以和整数进行乘法运算实现列表的重复。
[1,2,3] + [4,5,6]
[1, 2, 3, 4, 5, 6]
[1,2,3] * 3
[1, 2, 3, 1, 2, 3, 1, 2, 3]
2.3 列表的索引和切片
序列的切片操作完全一致,参见字符串
注意嵌套列表的元素获取
ls = [1,2,['a','b']]
ls[2][0]
'a'
2.4 列表的常用操作
python中的列表操作非常灵活,是非常重要和经常使用的数据类型。
2.4.1 修改元素
列表的中的元素可以进行修改,只需使用索引赋值即可。
ls = [1,2,3]
ls[1] = 'a'
print(ls)
[1, 'a', 3]
2.4.2 增加元素
给列表添加元素需要使用到列表的方法
.append(el),在列表的末尾添加一个元素
ls = [1,2,3]
ls.append(4)
print(ls)
[1, 2, 3, 4]
.insert(index, el),在列表的指定索引处插入一个元素
ls = [1,2,3]
ls.insert(0,0)
print(ls)
[0, 1, 2, 3]
.extend(iterable),扩展列表,元素为传入的可迭代对象中的元素
ls = [1,2,3]
ls.extend([4,5,6])
print(ls)
[1, 2, 3, 4, 5, 6]
2.4.3 删除元素
.pop(index=-1),删除指定索引的元素,并返回该元素,没有指定索引默认删除最后一个元素
ls = [1,2,3]
ls.pop()
3
print(ls)
[1, 2]
ls.pop(0)
1
print(ls)
[2]
.remove(value),从列表中删除第一个指定的值value,如不不存在value则报错。
ls = [1,2,3,1]
ls.remove(1)
print(ls)
[2, 3, 1]
.clear(),清空列表,原列表变成空列表
ls = [1,2,3]
ls.clear()
print(ls)
[]
2.5 列表的其他方法
.copy() 返回一个列表的浅拷贝。在讲可变与不可变类型的时候再详细讨论。
.count(value),统计列表中value的出现次数
ls = [1,2,3,1]
ls.count(1)
2
.index(self, value, start=0, stop=9223372036854775807),返回列表中指定值value的第一个索引,不存在则报错
ls = [1,2,3,1]
ls.index(1)
0
l.index(1,1)
3
.reverse(),翻转列表元素顺序
ls = [1,2,3]
ls.reverse()
print(ls)
[3, 2, 1]
.sort(key=None, reverse=False),对列表进行排序,默认按照从小到大的顺序,当参数reverse=True时,从大到小。注意列表中的元素类型需要相同,否则抛出异常。
ls = [2,1,3]
ls.sort()
print(ls)
[1, 2, 3]
# 从大到小
ls.sort(reverse=True)
print(ls)
[3, 2, 1]
ls = [1,2,'3']
ls.sort()
TypeError Traceback (most recent call last)
in
1 ls = [1,2,'3']
----> 2 ls.sort()
TypeError: '<' not supported between instances of 'str' and 'int'
2.6 字符串和列表的转换
字符串是字符组成的序列,可以通过 list函数将字符串转换成单个字符的列表。
s = 'hello world!'
ls = list(s)
print(ls)
['h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd', '!']
由字符组成的列表可以通过字符串的join方法进行拼接
# 接上面的案例
''.join(ls)
'hello world!'
3. 元组
元组(tuple)表示任意元素的序列,元素可以是任意数据类型,序列中的元素不能增,删,改,可以说元组就是不可变的列表。
3.1 元组的定义
元组通过一对小括号进行定义,元组之间使用逗号隔开。
a = () # 空元祖
b = ("a", "b", "cde") # 字符串
c = (1, "b", "c") # 数字
d = (1, "b", []) # 列表
e = (1, "b", (2, "c")) # 元祖
f = 1,2
print('a的类型为:', type(a)) # a的类型为: <class 'tuple'>
print('b的类型为:', type(b)) # b的类型为: <class 'tuple'>
print('c的类型为:', type(c)) # c的类型为: <class 'tuple'>
print('d的类型为:', type(d)) # d的类型为: <class 'tuple'>
print('e的类型为:', type(e)) # e的类型为: <class 'tuple'>
print('f的类型为:', type(f)) # f的类型为: <class 'tuple'>
a的类型为: <class 'tuple'>
b的类型为: <class 'tuple'>
c的类型为: <class 'tuple'>
d的类型为: <class 'tuple'>
e的类型为: <class 'tuple'>
f的类型为: <class 'tuple'>
注意单元素元组的定义,一定要多加个逗号
g = ('hello')
h = ('hello',)
print('g的类型为:', type(g)) # g的类型为: <class 'str'>
print('h的类型为:', type(h)) # h的类型为: <class 'tuple'>
g的类型为: <class 'str'>
h的类型为: <class 'tuple'>
3.2 元组的索引和切片
序列的索引和切片完全一致,参加字符串。
3.2 元组的常用操作
元组的元素不能修改,增加和删除,其他操作和列表的操作一致。
元组利用不可修改的特性,应用在多变量赋值和函数多返回值上。
a, b = (1, 2)
# 经常简写为a, b= 1, 2
当然多变量赋值时可以使用可迭代对象,但是元组最安全,它是不可变的。
关于函数多返回值的问题我们后面再讲
3.3 元组的常用方法
元组只有两个公有方法 count,index用法与列表相同。
3.4 len函数
python内建函数 len可以获取对象中包含的元素个数
s = 'hello'
ls = [1,2,3]
t = (1,2,3)
print(len(s))
print(len(ls))
print(len(t))
5
3
3
4. 可变与不可变对象
python中的对象根据底层内存机制分为可变与不可变两种。
可变对象可以在其 id()保持固定的情况下改变其取值。
下面的列表a,修改值后,id保持不变
a = [1,2,3]
id(a)
14053670614592
# 修改a的值
a[0] = 'a'
id(a)
# 修改a的值
a[0] = 'a'
id(a)
14053670614592
基本数据类型中列表,集合和字典都是可变数据类型。
如果修改一个对象的值,必须创建新的对象,那么这个对象就是不可变对象。
例如下面的字符串s,修改内容后id发生了改变。
s = 'hello'
id(s)
140453671058032
s = 'Hello'
id(s)
140453671058032
基本数据类型中数字,字符串,元组是不可变对象。
5.可哈希对象
一个对象的哈希值如果在其生命周期内绝不改变,就被称为可哈希。可哈希对象都可以通过内置函数hash进行求值。
它们在需要常量哈希值的地方起着重要的作用,例如作为集合中的元素,字典中的键。
不可变数据类型都是可哈希对象,可变数据类型都是不可哈希对象。
hash(1)
1
hash([1,2])
TypeError Traceback (most recent call last)
in
----> 1 hash([1,2])
TypeError: unhashable type: 'list'
6.赋值与深浅拷贝
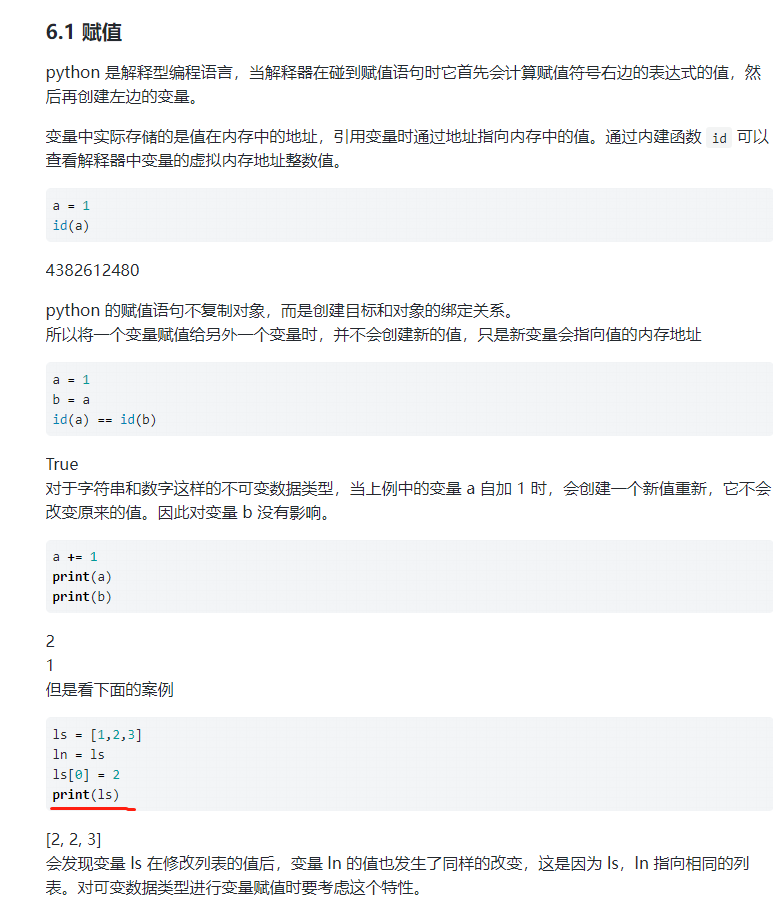
6.1 赋值
python是解释型编程语言,当解释器在碰到赋值语句时它首先会计算赋值符号右边的表达式的值,然后再创建左边的变量。
变量中实际存储的是值在内存中的地址,引用变量时通过地址指向内存中的值。通过内建函数 id可以查看解释器中变量的虚拟内存地址整数值。
a = 1
id(a)
4382612480
python的赋值语句不复制对象,而是创建目标和对象的绑定关系。
所以将一个变量赋值给另外一个变量时,并不会创建新的值,只是新变量会指向值的内存地址
a = 1
b = a
id(a) == id(b)
True
对于字符串和数字这样的不可变数据类型,当上例中的变量a自加1时,会创建一个新值重新,它不会改变原来的值。因此对变量b没有影响。
a += 1
print(a)
print(b)
2
1
但是看下面的案例
ls = [1,2,3]
ln = ls
ls[0] = 2
print(ls)
[2, 2, 3]
会发现变量ls在修改列表的值后,变量ln的值也发生了同样的改变,这是因为ls,ln指向相同的列表。对可变数据类型进行变量赋值时要考虑这个特性。
6.2 浅拷贝
导入 copy模块中的 copy函数就是浅拷贝操作
import copy
a = 123
s = 'hello'
b = copy.copy(a)
d = copy.copy(s)
print(id(a),id(b))
print(id(s),id(d))
4382616384 4382616384
140571355341296 140571355341296
对于字符串数字这种不可变数据类型来说,浅拷贝相当于变量赋值,所以变量a和b的id相等,变量s和d的id相等。
a += 1
print(a)
print(b)
124
123
对原变量的修改会创建新的值,不会影响浅拷贝生成的变量,变量a自加1后指向值124,变量b的值不变
对于可变数据类型,列表,字典,集合等浅拷贝会有不一样的结果。
ls = [1,'2',['a','b']]
ln = copy.copy(ls)
print(id(ls),id(ln))
140571352915648 140571355343040
当对可变数据类型进行浅拷贝时,会创建一个新的数据,所以变量ls和ln的id不想等。
print(id(ls[2]),id(ln[2]))
140571355288384 140571355288384
浅拷贝将原始对象中找到的对象引用插入其中。
也就是说,ls列表中的元素,ln中只是引用,ln中的每个对应位置指向的内存地址和ls相同。
ls[0] = 2
print(ls)
print(ln)
[2, '2', ['a', 'b']]
[1, '2', ['a', 'b']]
修改ls中第一个元素,因为是不可变数据类型,所以ls中第一个位置指向了新的内存地址,ln中的不变。
ls[2][0] = 1
print(ls)
print(ln)
[2, '2', [1, 'b']]
[1, '2', [1, 'b']]
修改ls中最后一个元素,因为是可变数据类型,所以ln中的值也发生了改变。
6.3 深拷贝
不可变数据类型的深浅拷贝一致。
复杂数据类型进行深拷贝会对数据中的所有元素完全重新复制一份,不管有多少层嵌套,互不影响。
import copy
ls = [1,2,3,['a', 'b']]
# 深拷贝使用deepcopy
ln = copy.deepcopy(ls)
ls[3][0]='b'
print(ls)
print(ln)
[1, 2, 3, ['b', 'b']]
[1, 2, 3, ['a', 'b']]
 发现老师的一个笔误
发现老师的一个笔误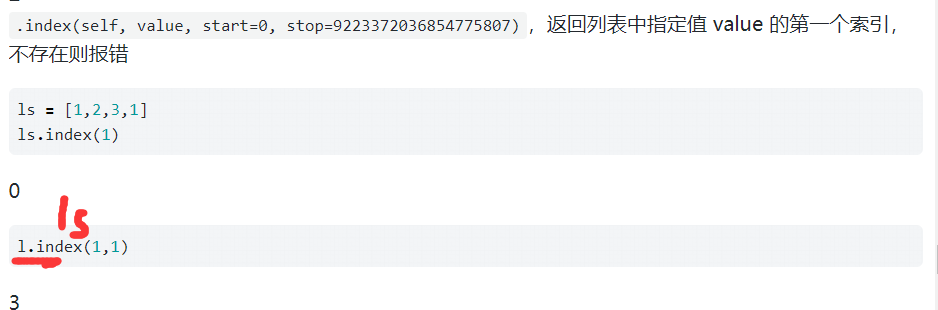
欢迎来到testingpai.com!
注册 关于