一、Redis主从复制架构
二、Redis主服务器的配置
- 进入到Redis主服务器的配置文件
[root@localhost redis]# vim redis.conf
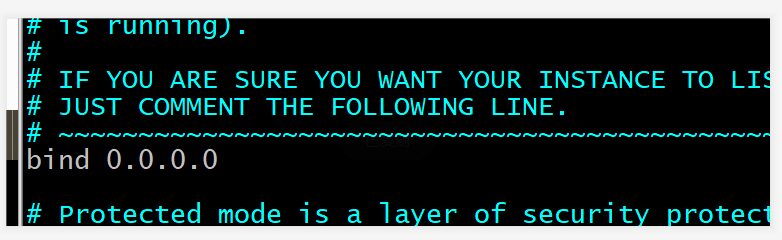
#可以注释或直接改成bind 0.0.0.0,所有的ip都可以访问
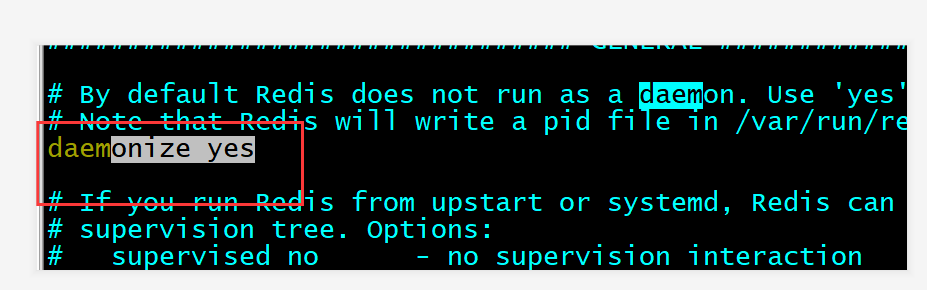
- 开启守护进程
- 重启Redis服务
[root@localhost redis]# service redis restart

三、配置从服务
前面两步主服务器配置一样
- 复制一个rdis.conf配置文件,比如文件名为:
[root@localhost redis]# cp redis.conf redis_6380.conf
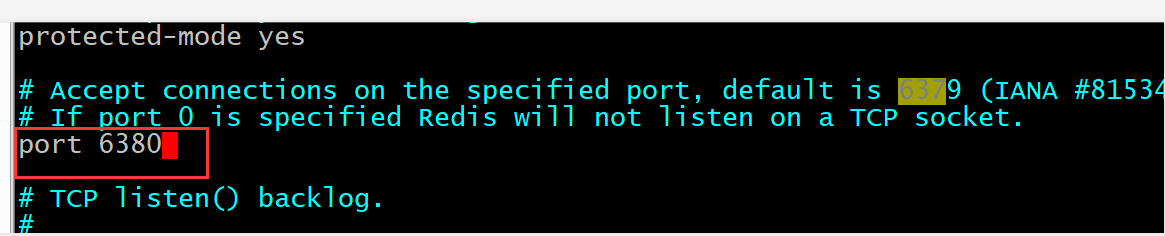
- 修改端口
[root@localhost redis]# vim redis_6380.conf
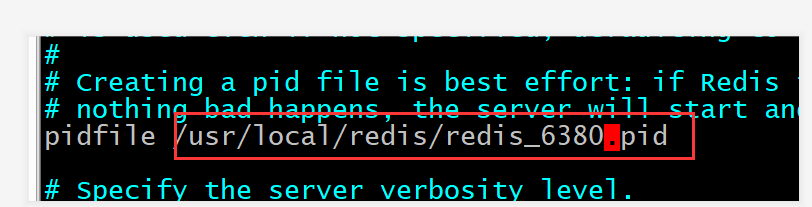
- 修改pid生成的路径
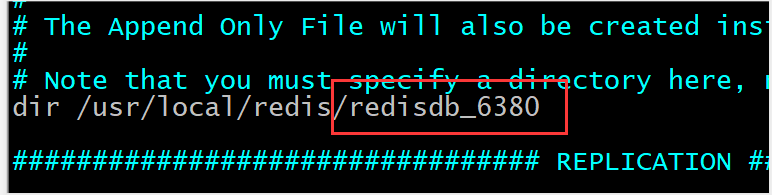
- 修改数据保存的名称
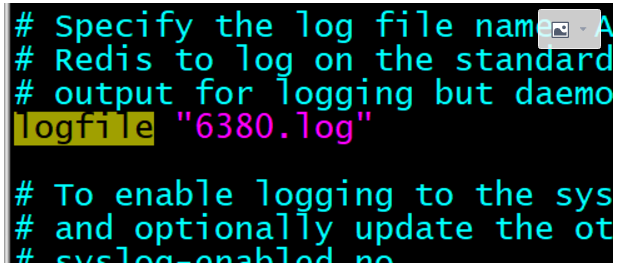
- 修改日志信息
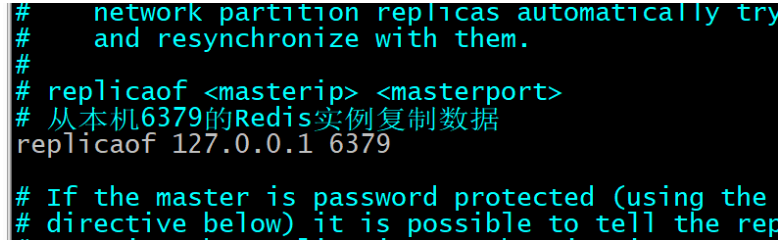
- 配置主Redis的ip和端口
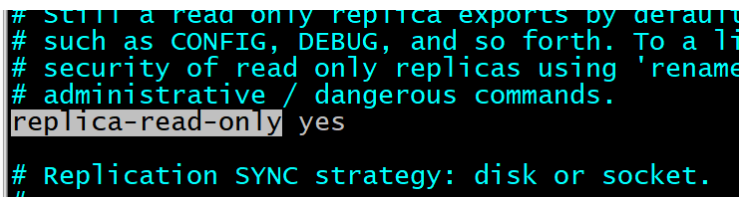
- 启动从节点
[root@localhost redis]# /usr/local/redis/bin/redis-server /usr/local/redis/redis_6380.conf
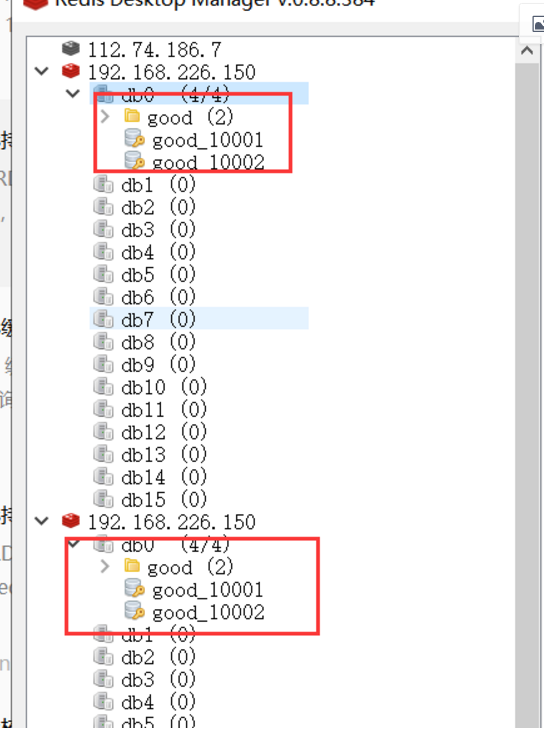
- 查看从节点的数据,已经把主节点的数据同步过来了
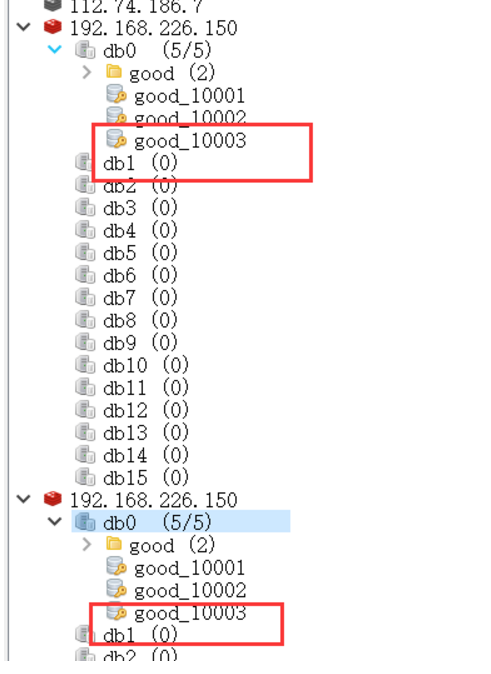
- 新增数据
四、主从复制的流程(全量)
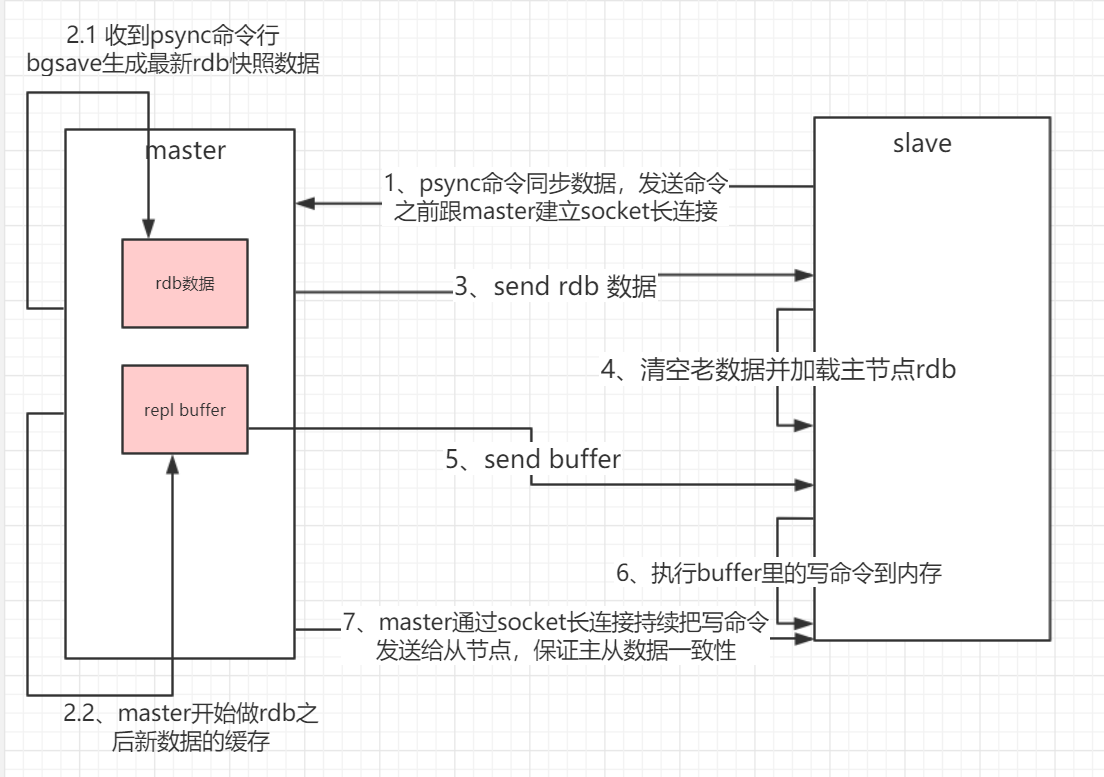
- master配置了一个slave,slave连接上Master,就会发送一个PSYNC命令给master请求复制数据。
- master收到PSYNC命令后,在后台进行数据持久化,通过bgsave生成最新的rdb快照文件,持久化期间,master会继续接收客户端的请求,会把这些可能修改数据集的请求缓存在内存中。
- 当持久化进行完毕以后,master会把这份rdb文件数据集发送给slave
- slave会把接收到的数据进行持久化生成rdb,然后再加载到内存中
- master再将之前缓存在内存中的命令发送给slave。
- 当master与slave之间的连接由于某些原因而断开时,slave能够自动重连Master
- 如果master收到了多个slave并发连接请求,它只会进行一次持久化,而不是一个连接一次,再把这一份持久化的数据发送给多个并发连接的slave
五、主从复制(部分复制,断点续传)流程图:
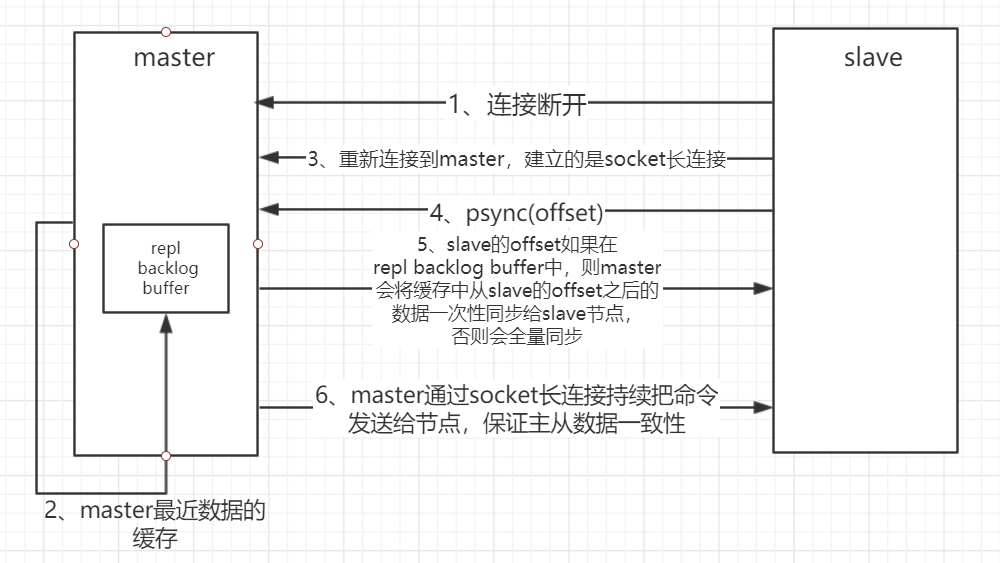
- 当master和slave断开重连后,一般都会对整份数据进行复制。但从redis2.8版本开始,redis改用可以支持部分数据复制的命令PSYNC去master同步数据,slave与master能够在网络连接断开重连后只进行部分数据复制(断点续传)。
- master在其内存中创建一个复制数据用的缓存队列,缓存最近一段时间的数据
- master和它所有的slave都维护了复制的数据下标offset和master的进程id
- 因此,当网络连接断开后,slave会请求master继续进行未完成的复制,从所记录的数据下标开始
- 如果master进程id变化了,或者从节点数据下标offset太旧,已经不在master的缓存队列里了,那么将会进行一次全量数据的复制。
欢迎来到testingpai.com!
注册 关于