模板渲染
django框架大而全,所以其代码的调用异常复杂,不便文字表述,我将其基本函数调用画成流程图如下:
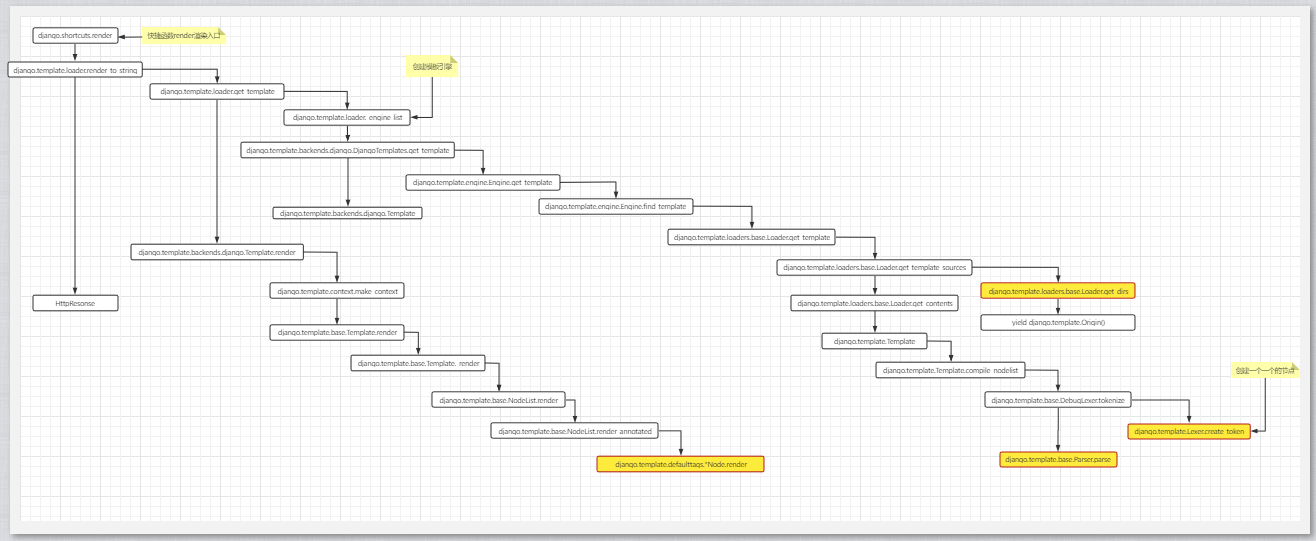
详细流程图请点击
模板渲染的主要流程如下:
- 查找模板,并获取完整路径
- 读取模板的文本内容
- 对文本内容通过模板语言的格式进行分割,形成一个节点列表,节点有各种类型,例如文本型,变量型,标签型等等。
- 然后分别调用各个节点的渲染函数,进行渲染
- 按照节点列表里的顺序,把各节点的渲染后的字符串进行拼接返回。
下面我抽取部分核心业务的源码进行分析,主要分析以注释的形式写在代码中
查找模板的逻辑
django.template.loaders.filesystem.Loader.get_template_source
这个方法是获取所有的模板路径。
def get_template_sources(self, template_name):
"""
Return an Origin object pointing to an absolute path in each directory
in template_dirs. For security reasons, if a path doesn't lie inside
one of the template_dirs it is excluded from the result set.
"""
for template_dir in self.get_dirs(): # 查找所有的模板路径
try:
name = safe_join(template_dir, template_name) # 拼接模板文件的全路径
except SuspiciousFileOperation:
# The joined path was located outside of this template_dir
# (it might be inside another one, so this isn't fatal).
continue
yield Origin(
name=name,
template_name=template_name,
loader=self,
)
再看self.get_dirs()
def get_dirs(self):
return self.dirs if self.dirs is not None else self.engine.dirs
所以我们需要看engine的创建过程,它在django.template.loader._engine_list方法中调用
def _engine_list(using=None):
return engines.all() if using is None else [engines[using]]
查看这个方法有个一个engines的变量,查看它的导入路径from . import engines,在往上追,在django.template.loaders.__init__.py中看到了它的定义
from .engine import Engine
from .utils import EngineHandler
engines = EngineHandler() #
__all__ = ('Engine', 'engines')
说明在启动项目时,就已经把所有的模板路径加载了,查看EngineHandler的源码,发现一个方法如下:
@functools.lru_cache()
def get_app_template_dirs(dirname):
"""
Return an iterable of paths of directories to load app templates from.
dirname is the name of the subdirectory containing templates inside
installed applications.
"""
template_dirs = [
Path(app_config.path) / dirname
for app_config in apps.get_app_configs()
if app_config.path and (Path(app_config.path) / dirname).is_dir()
]
# Immutable return value because it will be cached and shared by callers.
return tuple(template_dirs)
这里很清晰的看到template_dirs的创建过程。
创建节点的逻辑
创建节点列表的逻辑在django.template.Template的初始化方法中
def compile_nodelist(self):
"""
Parse and compile the template source into a nodelist. If debug
is True and an exception occurs during parsing, the exception is
annotated with contextual line information where it occurred in the
template source.
"""
# 创建解析器
if self.engine.debug:
lexer = DebugLexer(self.source)
else:
lexer = Lexer(self.source)
# 根据各种标签变量的语法对模板字符串进行分割解析
tokens = lexer.tokenize()
parser = Parser(
tokens, self.engine.template_libraries, self.engine.template_builtins,
self.origin,
)
try:
return parser.parse()
except Exception as e:
if self.engine.debug:
e.template_debug = self.get_exception_info(e, e.token)
raise
再看django.template.base.DebugLexer.tokenize
def tokenize(self):
"""
Split a template string into tokens and annotates each token with its
start and end position in the source. This is slower than the default
lexer so only use it when debug is True.
"""
lineno = 1
result = []
upto = 0
# 这里的tag_re是一个正则表达式对象
# 通过匹配把模板字符串分割成文本,变量,标签等类别
# 再通过creat_token方法创建成各种类型的node
for match in tag_re.finditer(self.template_string):
start, end = match.span()
if start > upto:
token_string = self.template_string[upto:start]
result.append(self.create_token(token_string, (upto, start), lineno, in_tag=False))
lineno += token_string.count('\n')
token_string = self.template_string[start:end]
result.append(self.create_token(token_string, (start, end), lineno, in_tag=True))
lineno += token_string.count('\n')
upto = end
last_bit = self.template_string[upto:]
if last_bit:
result.append(self.create_token(last_bit, (upto, upto + len(last_bit)), lineno, in_tag=False))
return result
来看一下tag_re的源码,它就定义在django.template.base中
tag_re = (_lazy_re_compile('(%s.*?%s|%s.*?%s|%s.*?%s)' %
(re.escape(BLOCK_TAG_START), re.escape(BLOCK_TAG_END),
re.escape(VARIABLE_TAG_START), re.escape(VARIABLE_TAG_END),
re.escape(COMMENT_TAG_START), re.escape(COMMENT_TAG_END))))
它的正在表达式如下:
'(\\{%.*?%\\}|\\{\\{.*?\\}\\}|\\{\\#.*?\\#\\})'
可以看到分别对应,模板标签语法{% %},模板变量语法{{ }},模板注释语法 {# #}。
我们再看create_token方法
def create_token(self, token_string, position, lineno, in_tag):
"""
Convert the given token string into a new Token object and return it.
If in_tag is True, we are processing something that matched a tag,
otherwise it should be treated as a literal string.
"""
if in_tag and token_string.startswith(BLOCK_TAG_START):
# The [2:-2] ranges below strip off *_TAG_START and *_TAG_END.
# We could do len(BLOCK_TAG_START) to be more "correct", but we've
# hard-coded the 2s here for performance. And it's not like
# the TAG_START values are going to change anytime, anyway.
block_content = token_string[2:-2].strip()
if self.verbatim and block_content == self.verbatim:
self.verbatim = False
if in_tag and not self.verbatim:
# 这里是判断是否是模板变量
if token_string.startswith(VARIABLE_TAG_START):
return Token(TokenType.VAR, token_string[2:-2].strip(), position, lineno)
# 这里是判断是否是模板标签
elif token_string.startswith(BLOCK_TAG_START):
if block_content[:9] in ('verbatim', 'verbatim '):
self.verbatim = 'end%s' % block_content
return Token(TokenType.BLOCK, block_content, position, lineno)
# 这里是判断是否是注释
elif token_string.startswith(COMMENT_TAG_START):
content = ''
if token_string.find(TRANSLATOR_COMMENT_MARK):
content = token_string[2:-2].strip()
return Token(TokenType.COMMENT, content, position, lineno)
else:
# 都不是就是文本标签
return Token(TokenType.TEXT, token_string, position, lineno)
不同节点渲染的逻辑
变量节点
模板中的模板变量都会被封装成变量节点django.template.base.VariableNode。
class VariableNode(Node):
def __init__(self, filter_expression):
self.filter_expression = filter_expression
def __repr__(self):
return "<Variable Node: %s>" % self.filter_expression
def render(self, context):
# 这里的context就是上下文,包含系统上下文,和调用时传入的上下文
try:
output = self.filter_expression.resolve(context)
except UnicodeDecodeError:
# Unicode conversion can fail sometimes for reasons out of our
# control (e.g. exception rendering). In that case, we fail
# quietly.
return ''
return render_value_in_context(output, context)
对render继续进行调用跟踪, 最后发现它又调用了django.template.base.Variable.resolve
def resolve(self, context):
"""Resolve this variable against a given context."""
# 如果是一个没有解析的变量节点self.lookups就是变量表达式字符串
if self.lookups is not None:
# We're dealing with a variable that needs to be resolved
# 进一步解析
value = self._resolve_lookup(context)
else:
# We're dealing with a literal, so it's already been "resolved"
value = self.literal
# 这里做一些转义和xss攻击的处理
if self.translate:
is_safe = isinstance(value, SafeData)
msgid = value.replace('%', '%%')
msgid = mark_safe(msgid) if is_safe else msgid
if self.message_context:
return pgettext_lazy(self.message_context, msgid)
else:
return gettext_lazy(msgid)
return value
再看self._resolve_lookup(context),这个方法里可以看到变量的渲染逻辑
def _resolve_lookup(self, context):
"""
Perform resolution of a real variable (i.e. not a literal) against the
given context.
As indicated by the method's name, this method is an implementation
detail and shouldn't be called by external code. Use Variable.resolve()
instead.
"""
current = context
try: # catch-all for silent variable failures
for bit in self.lookups:
try: # dictionary lookup 1. 先尝试字典取值
current = current[bit]
# ValueError/IndexError are for numpy.array lookup on
# numpy < 1.9 and 1.9+ respectively
except (TypeError, AttributeError, KeyError, ValueError, IndexError):
try: # attribute lookup 2. 再尝试属性取值
# Don't return class attributes if the class is the context:
if isinstance(current, BaseContext) and getattr(type(current), bit):
raise AttributeError
current = getattr(current, bit)
except (TypeError, AttributeError):
# Reraise if the exception was raised by a @property
if not isinstance(current, BaseContext) and bit in dir(current):
raise
try: # list-index lookup 3. 再尝试索引取值
current = current[int(bit)]
except (IndexError, # list index out of range
ValueError, # invalid literal for int()
KeyError, # current is a dict without `int(bit)` key
TypeError): # unsubscriptable object
raise VariableDoesNotExist("Failed lookup for key "
"[%s] in %r",
(bit, current)) # missing attribute
if callable(current): # 4. 在判断是否是可调用
if getattr(current, 'do_not_call_in_templates', False):
pass
elif getattr(current, 'alters_data', False):
current = context.template.engine.string_if_invalid
else:
try: # method call (assuming no args required)
current = current()
except TypeError:
signature = inspect.signature(current)
try:
signature.bind()
except TypeError: # arguments *were* required
current = context.template.engine.string_if_invalid # invalid method call
else:
raise
except Exception as e:
template_name = getattr(context, 'template_name', None) or 'unknown'
logger.debug(
"Exception while resolving variable '%s' in template '%s'.",
bit,
template_name,
exc_info=True,
)
if getattr(e, 'silent_variable_failure', False):
current = context.template.engine.string_if_invalid
else:
raise
return current
欢迎来到testingpai.com!
注册 关于