MySQL服务演进
概述
- 当数据越来越多,且增长速度很快,尤其是并发量也越来越多时,单点的数据库会出现性能瓶颈,比如连接池连接数不够,很多请求处于阻塞状态,没有命中索引的查询非常耗时,物理存储也会压力倍增
- 此时,需要对数据库进行优化,硬件层面,增加CPU、内存和存储空间在前期能解决一定的问题;
- 更多的,需要通过软件层面来进行优化,包括:
- SQL调优,如前面所讲,排查出慢查询,有针对性进行优化
- 表结构优化,根据业务特性,只返回表中合理数据,或表根据业务拆分成多个表,另外,适当的冗余,也能减少join,提升查询性能
- 读写分离,面向实际业务读多写少的实际情况,使用binlog同步实现一主多从多个数据库实例,提升性能
- 分库分表,但数据量继续增加时,尤其是单表数据超大,比如超过500
业务演进...
- 就像一个公司是从小到大,业务体量也是如此,一般的,一个业务系统正常演进如下:
- 单业务系统à单数据库:此时,业务体量很小,数据库承载量充分并有富余
- 多业务系统à单数据库:这个阶段,业务复杂度增大,会将复杂的业务系统拆分成很多子业务系统,数据库性能卓越,还能继续支持多业务系统
- 多业务系统à多数据库:即按业务分库、业务量继续增大,数据库成为瓶颈,将数据库按每个业务系统单独划分独立的数据库,独立部署,增加各个系统的业务承载能力,整体业务的承载能力也增强,微服务的处理模式就是这样
- 分库分表:业务进入持续快速增长,某些业务子系统的单个或多个业务表数据量超限,通过硬件提升、单表的SQL优化、甚至时读写分离,都不能有效提高查询或操作的性能,就需要使用分表处理了;主要有垂直分表和水平分表,垂直分表是按业务特性,单表只存放与业务相关的字段;当数据量达到足够大时,如超过500万条记录,垂直分表性能提升有限,最终还是要使用分库的水平分表
- 垂直分表:按业务拆分成多个表结构,使表结构更聚焦于业务,减少查询返回数据量
- 水平分表:表结构相同,基于不同维度划分数据,数据不相同;又分单库分表和多库分表,由于单库始终会有性能瓶颈,所以常见为多库分表
业务演进过程
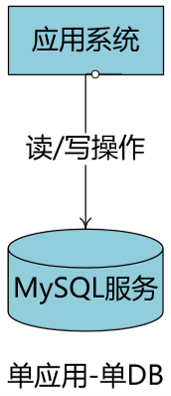
单应用-单DB
-
小型项目的常见业务形态

多应用-单DB
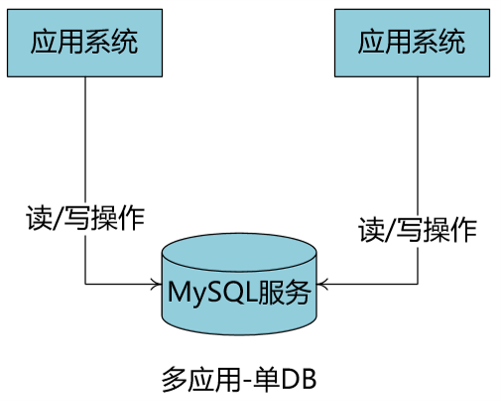
-
企业具备多种小项目常见的业务形态,数据库服务需要性能相对较好
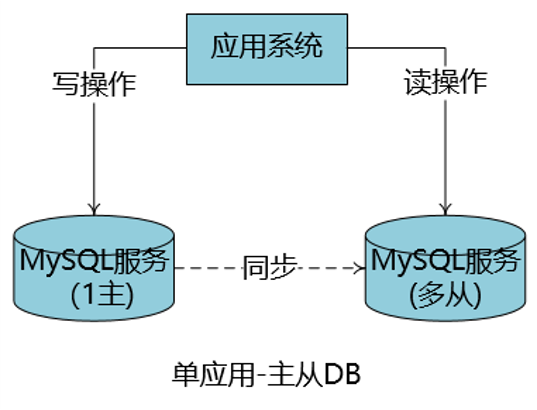
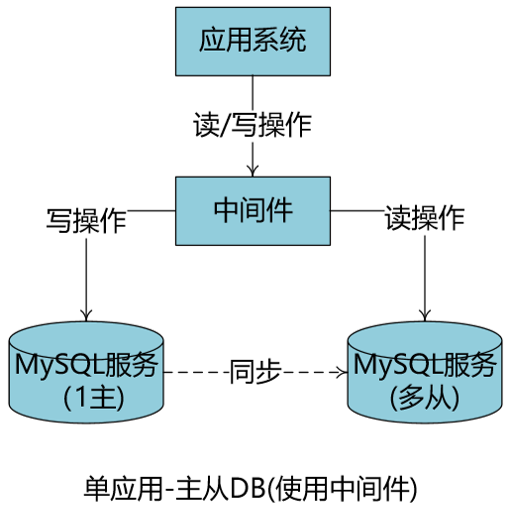
单应用-主从DB
-
中型复杂业务系统常见的模式,将业务中的读操作、写操作针对不同的DB服务器,提升业务系统容量
-
主、从DB服务器要有合理的数据同步机制
-
可以直接业务中切换,也可以使用中间件
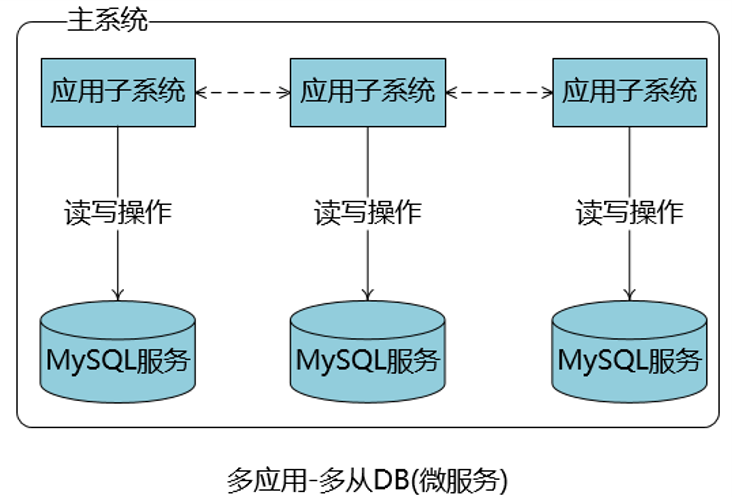
多应用-多DB
-
从业务的角度将应用、DB都做切分,切分成粒度更小的多个应用+DB组合
-
微服务就是典型的多应用-多DB的模式
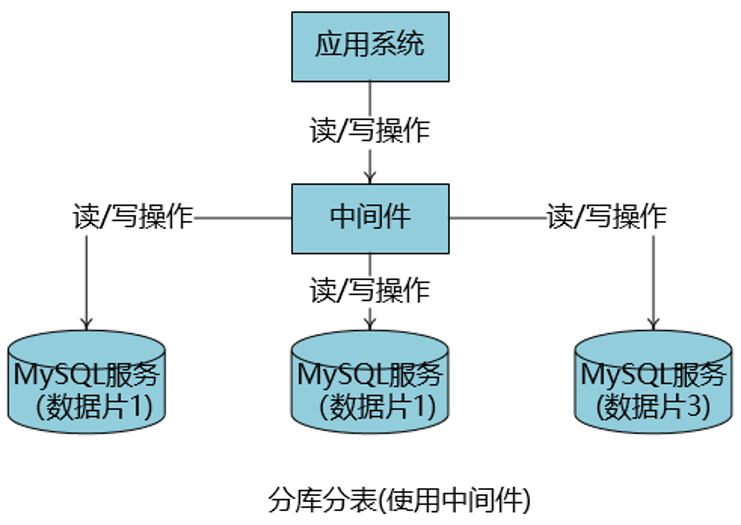
分库分表
-
当应用体量越来越大,部分业务的单表数据超大,如超过1000万条,此时要考虑分库分表
-
分库分表给应用带来了很大的复杂性,一般会使用像MyCat、ShardingSphere等中间件来处理,给业务屏蔽DB的复杂性
如何分表?
- 实现分表,核心的就是根据业务找到一个合理的分表键,一般要考虑几个条件:
- 数据能尽量均匀的分布在不同的库或表,并考虑业务增长的特性
- 跨度查询,尤其是跨库join查询尽量少
- 该分表键尽量不会变动
- 常用的分表键划分(分区)策略有按范围、hash、hash+范围等
分表带来的问题
- 跨库关联查询,如果在单库,可以方便的使用join获取关联信息、生成需要的业务报表,但分表后可能join的数据在另外一个库中;一般使用适当冗余数据、所有库都存放全局表、使用集中数据仓库处理汇总业务,以及在业务层组装等解决
- 分布式事务,一个库中事务好处理,跨库、跨业务的事务比较复杂;可考虑在业务层面上使用消息中间件,以及一些第三方组件Seata、TXLcn等使用两阶段提交方式处理
- 排序、分页、汇总等函数计算问题,需要分库计算、然后汇总,或是使用第三方组件
- 分布式ID,分库分表后,原有的表主键使用方式(如自增)可能会出现问题,主要解决方式有:UUID、号段模式、Redis缓存、雪花算法(SnowFlake)
第三方插件和中间件
- 分库分表后,业务系统中实现对多个数据源的数据操作实际很复杂
- 有业界的第三方插件或中间件来解决前述分库分表带来的问题
- ShardingSphere:Apache的开源的一个项目,需要嵌入到业务系统代码中进行处理,有基于Spring Boot的工具,对代码有侵入
- MyCat:是在业务系统与分库分表多数据源中间架设一个中间层来实现,对代码无侵入
欢迎来到testingpai.com!
注册 关于