概述
-
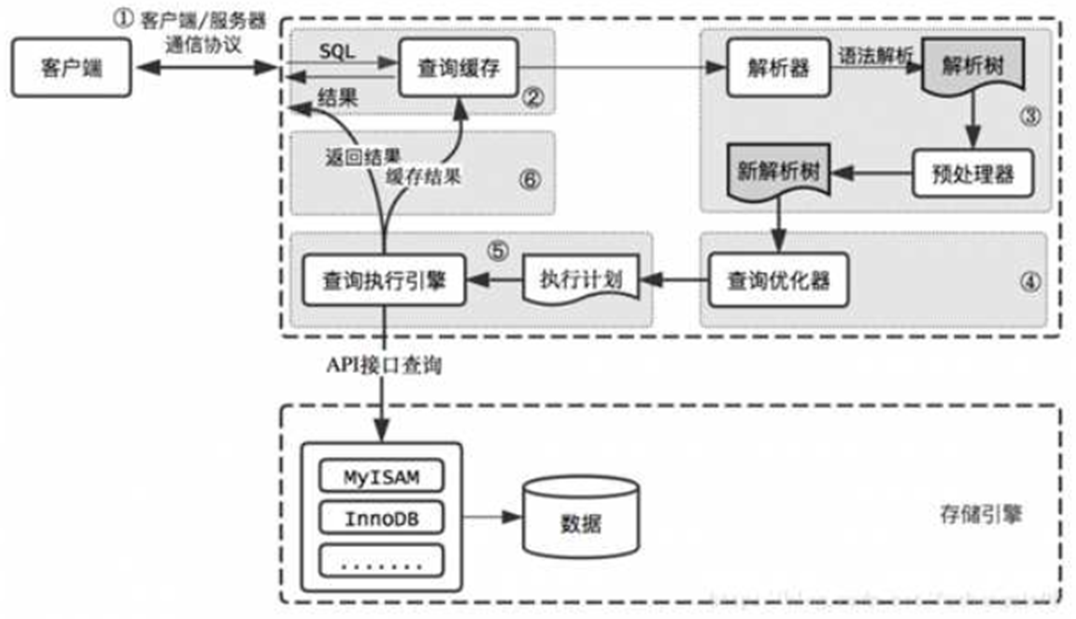
如下图,描述了MySQL一条语句执行的整体过程(图片来自网络)
-
在这个执行过程中,MySQL本身会对查询进行一定的优化处理
-
查询缓存,默认不开放,使用key-value形式的缓存
-
查询优化器,对于一些复杂的查询,MySQL内部拆分语法后,其实有多种执行方案,会依照不同表的数据量、索引使用情况,选择最优执行方案;分逻辑优化和物理优化,逻辑优化主要优化语句,物理优化则注重查看对表的扫描情况

为什么查询会慢?
- 需要检查业务,跟踪查询语句,要看:
- 是否向请求了不需要的数据,如不需要的记录或列、join了不需要的表、使用*返回了所有数据、重复查询了全部或部分数据
- 是否扫描了额外的记录,可以开启慢查询日志进行监控,开启方法在附件中
- 是否业务表的数据量过大,且查询条件未命中索引
开启MySQL慢查询
- 目的:找到慢查询语句
- 通过MySQL提供的机制,可以打开慢查询记录,并根据业务需要设置慢查询的阀值
- 一般这种操作多是DBA进行
- 一些云端的数据库产品,提供了慢查询的监控、语句查询时长监控等更多的服务
- 具体操作:慢查询开启及相关操作.sql
- 注意:上述开启的方式,重启MySQL后,会重置为默认值,可以通过/etc/my.cnf进行配置
如何优化慢查询?
- 从业务角度看,需要做以下几个方面的工作:
- 重构查询方式,对于一个业务,是使用一个复杂查询,还是组合多个简单查询?一般的MySQL服务器上,哪怕数据达到百万,如果查询能命中索引,效率也是很高的,但同时要兼顾网络传输、客户端处理数据的复杂度;所以在很多场景下,将一个大查询分解成多个简单的小查询是能有效提高效率
- 从业务角度切分查询,如一个大量数据的删除、全表的查询、全表批量更新等,相应操作还涉及到MySQL的日志等处理,拆分更小的查询性能更优,像分页查询
- 分解关联查询,尽量一次只对一个表进行查询,可使用到查询缓存、减少锁的竞争;多表的关联尽量在业务层进行
- 控制单次业务的查询次数,如程序中尽量不要在循环中进行数据库访问
- ...
慢查询优化实践
- 合理添加索引,如果针对某些列经常做搜索、关联、条件比较,就创建为索引列;但创建了索引列,查询时并不一定会命中,要通过EXPLAIN查看并调整语句
- 优化数据结构,将字段分解到多个表、对一些经常要呈现的外部关联数据,如果变化不大或符合业务,冗余进来提高查询效率;比如关联姓名、复杂层级数据关联所有的id
- 子查询优化,比如,where条件中的in效率要比exists差
- 关联查询优化,比如,给join中on关联的列添加索引;让group by或order by表达式中的列只涉及到一个表中的列,能有效使用索引;多个表关联查询时,索引使用会受限,如果其中有个大数据量的表,尽量要利用此表索引(比如此表单独改子查询先过滤数据)
注意,还有很多,如果where多个条件顺序不同,效率都不同,在实际的工作中,当单表数据达到一定数量,再去处理,或和DBA协同处理即可
欢迎来到testingpai.com!
注册 关于