数据库在测试工作过程中的使用总是无处不在的,总结一下最主要的两个场景如下:
1)确认系统测试和接口测试的测试结果,以及进行问题定位分析;
2)在项目中构造测试数据,比如当项目要做性能测试需要大量数据,需要测试搜索或者检查数据一致性的等,都需要构造大量的数据。
定位问题很多同学可能在项目里多少都遇到过一些,毕竟是简单的查询就可以实现的。但是构造数据如何实现呢?特别是当构造大量的数据的时候,比如百万数据的时候,应该如何实现呢?
构造测试数据方法
构造数据的方法比较多,比如:
方法一:在页面上手动操作添加
这种方式比较原始,简单操作,但是效率极低。如果只是少量的数据还有可操作性,一旦需要大量的数据比如几千、几万、甚至百万条数据,手动添加都是不现实的。
方法二:通过调用接口批量操作添加
这个也是可以的,使用接口工具批量操作,不过这个容易受到接口本身业务的限制,特别是涉及到接口的依赖和数据关联的时候,操作是比较麻烦的,而且容易被接口本身的性能影响操作效率;
方法三:在数据库里直接生成数据
这种方式比较直接而且比较高效。那么如何操作呢?
首选我们建好表:
CREATE TABLE tuser (
id INT PRIMARY KEY NOT NULL auto_increment,
username VARCHAR ( 25 ),
phone CHAR ( 11 )) DEFAULT CHARSET = utf8;
有了表之后,当然不推荐大家通过手动去数据库表里直接操作,这个跟页面操作效率也差不多。也不推荐使用insert int语句一条条的插入,效率也非常低。这里给大家推荐两种方式:
1、从外部导入excel表格导入数据。
1)首先在现有的excel表格里手动插入数据,格式按照数据库的表的字段来填充,可以通过下拉操作快速生成大量数据,比如100-1000个,并且可以控制是否递增出不一样的数据。
2)然后,在数据库的连接工具比如navicat工具里进行导入:
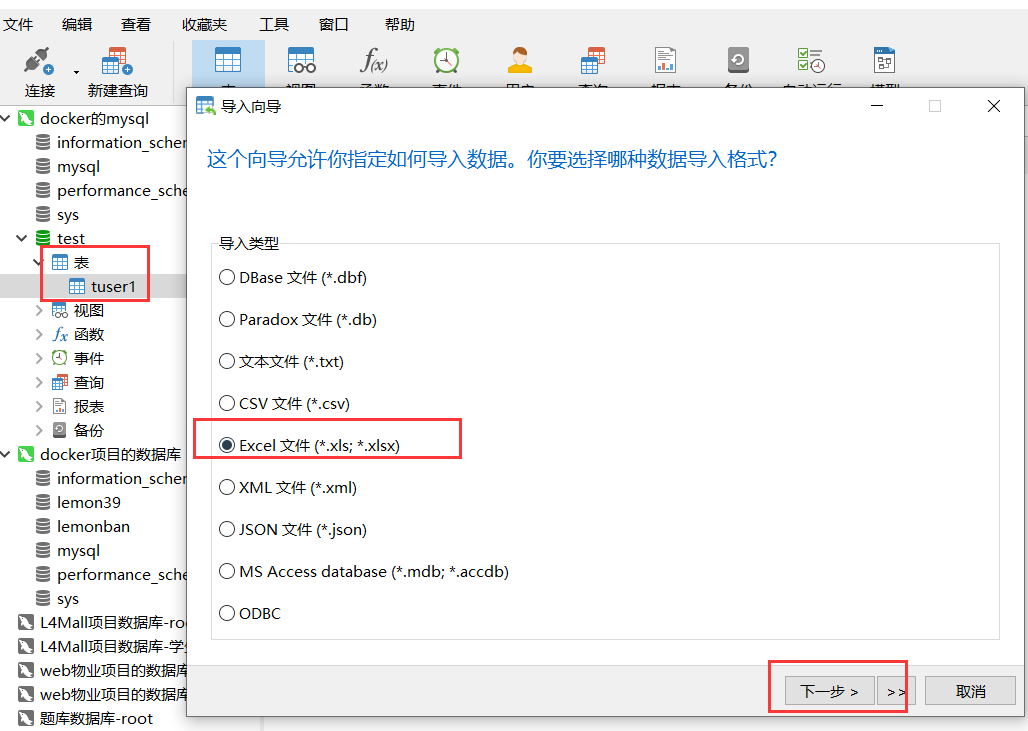
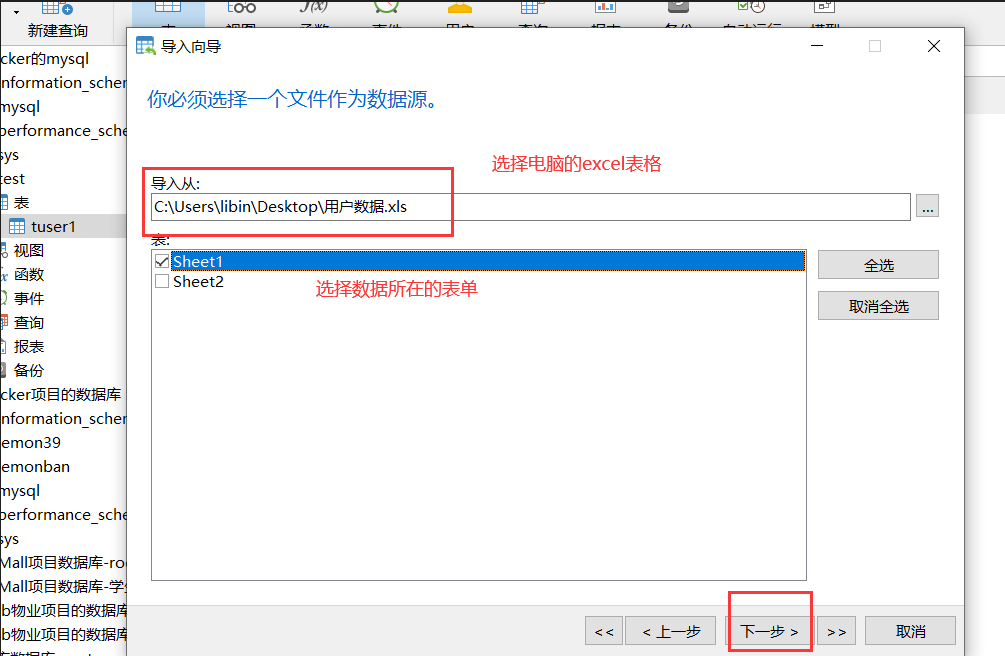
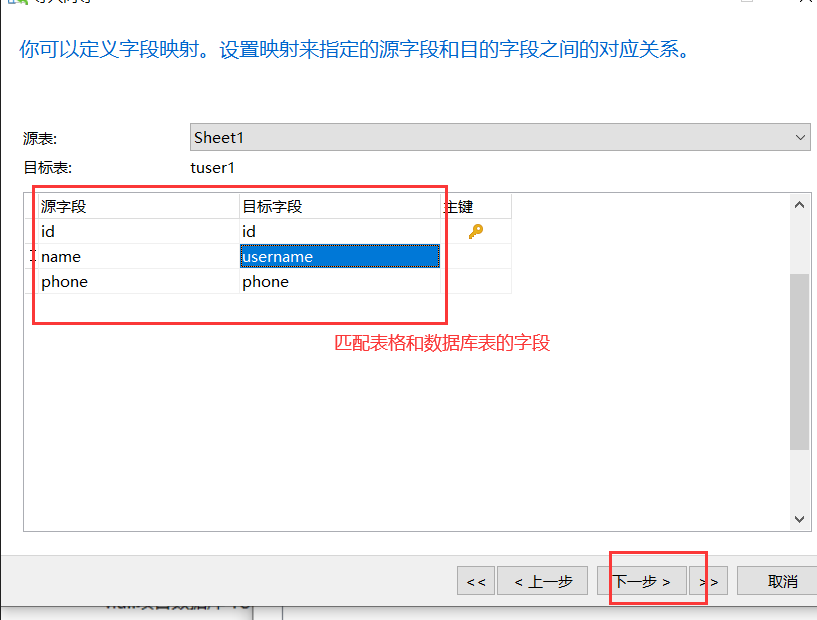
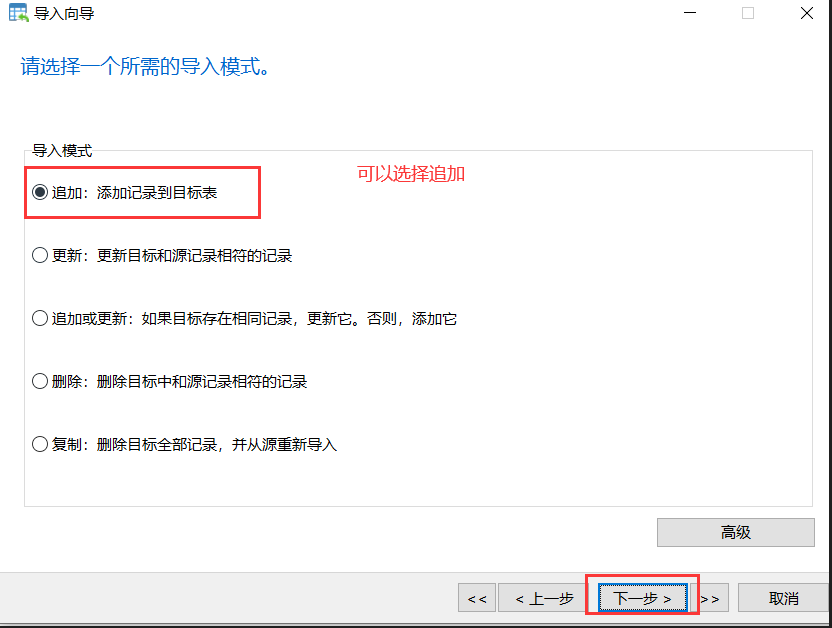
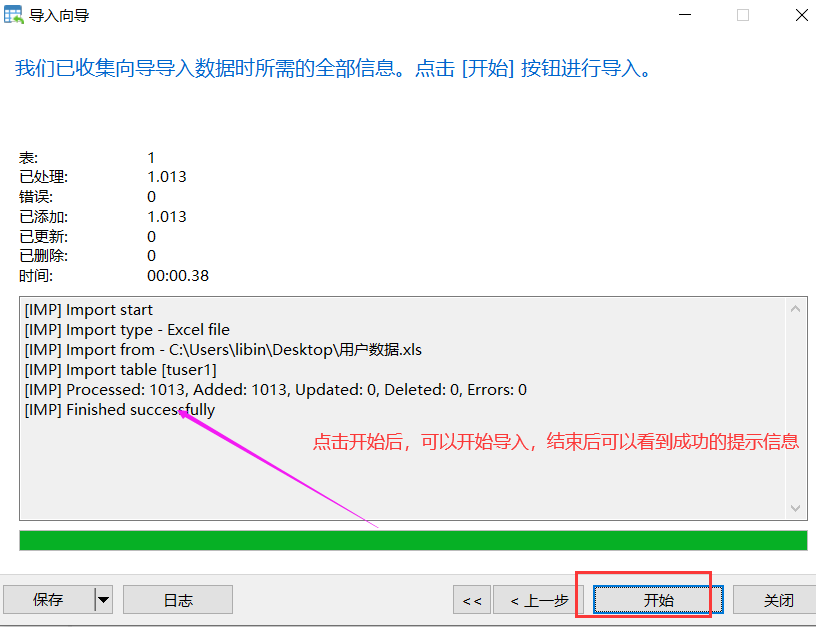
3)导入完成后,可以去检查表里数据的数量。
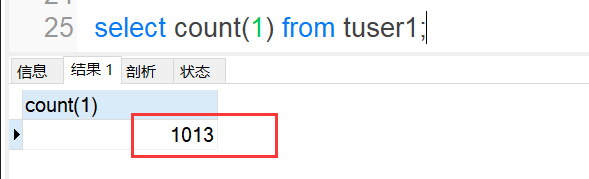
说明数据插入成功了。
这种方式可以插入1000条左右的数据,但是如果还需要更多,excel的拖动操作就操作性不强了。这个时候我们可以用数据库的存储过程实现。
2、数据库的存储过程生成数据。
-- 定义一个存储过程 batch_insert() 来批量插入数据:
drop PROCEDURE if exists batch_insert;
create PROCEDURE batch_insert()
begin
declare i int;
set i =1;
while i <= 1000000 do
insert into tuser (username,phone) values ("tricy","13455667788");
set i = i + 1;
end while;
end
-- 调用存储过程运行插入:
call batch_insert();
如上编写的存储过程,可以再2分钟内生成百万的测试数据。而且如果要求数据差异化,可以优化如下的:
-- 定义一个存储过程 batch_insert() 来批量插入数据:
drop procedure if exists batch_insert;
create procedure batch_insert()
begin
-- 定义一个变量
declare i int;
declare _name varchar(25);
declare _phone char(11);
set i=1;
while i<=1000000 do
set _name = concat('tom-',i); # 差异化每条数据的用户名
set _phone = 13000000000+i; # 差异化每条数据的手号码
insert into tuser(username,phone) values(_name,_phone);
set i=i+1;
end while;
end
-- 运行存储过程
call batch_insert();
如此可以实现分分钟插入百万数据的需求,可以快速的提升我们的测试效率。
欢迎来到testingpai.com!
注册 关于