前言
性能测试的结果分析是作为性能测试工程师的必修课,特别是监控服务器的资源使用情况,对于分析服务器的性能非常关键。我们有高很多的Linux的命令可以去监控各种资源,比如top,vmstat,iostat,pidstat等,但是命令使用有一定的门槛,结果看起来也没那么直观,所以现在很多公司都用Prometheus+grafana+export方案来进行资源监控。今天我们就给大家详细介绍一下这套方案的实施落地。
1、Grafana
grafana之前已经有文章介绍过了,需要的同学可以去获取: Jmeter+influxdb+grafana 性能测试结果监控
安装好了之后,通过web页面访问grafana服务并登录进去:http://机器ip:3000,打开grafana的监控大屏页面。
2、Prometheus
Prometheus 是由 SoundCloud 开源监控告警解决方案。它用时序数据的方式存储数据,有独立的 PromQL (Prometheus Query Language) 数据查询语言。
特点:
- 监控告警:可以监控到一些指标后,产生一下告警等事件的联动,比如cpu90% 内存 GC等 行为产生告警;
- 开源的,可以进行灵活的定制
- 是一种时序数据库,但是功能比influxdb更强大,可以跟更多的插件进行集成,数据都可以写到prometheus,相对来说更强大。
安装:
注意:不要安装在被测服务器,会影响被测试服务器的性能资源。
- 第一步:下载安装包传到服务器上进行解压:tar -xzvf prometheus-2.20.1.linux-amd64.tar.gz
- 第二步: 启动这个 prometheus服务 , ./promethues &
- 第三步:验证是否启动成功: http://服务器IP地址:9090/graph 可以访问到页面。说明没有问题。
- Prometheus的端口默认是9090。
3、Export
但是,我们需要注意的是Prometheus 本身不具有数据收集功能,只能存放数据 ,不能主动收集数据 。所以要从被测服务器上收集数据,需要通过其他的工具push数据进去,这个工具就是各种Export。
export是监控工具:主要用于收集服务器资源利用率情况,需要安装在被监听的服务器上。
- 可以监控数据,并定时的发送给prometheus存储在数据库里。
- 每个场景有不同的export,需要监听不同的数据 就需要使用不同的export。
- 如果你有多台被监控的服务器都需要收集数据,那么就需要多台服务器上都上传这个exporter。
下表是一些常用的Export类型以及其可以监控的数据:
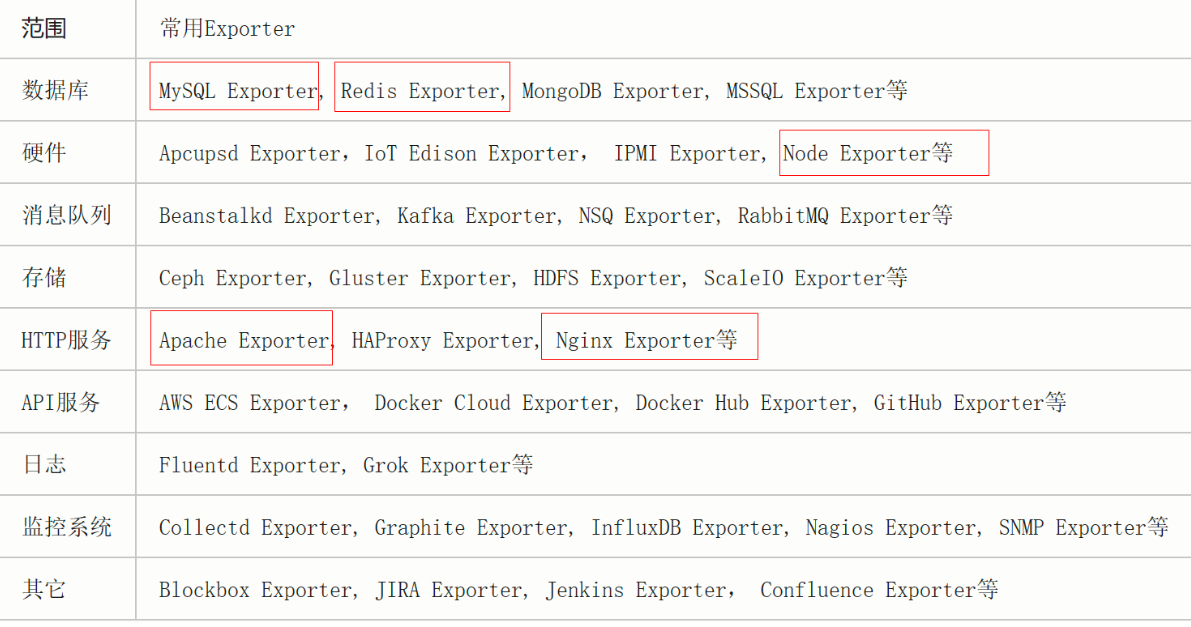
比如,我们要监控服务器的硬件资源,比如CPU、内存,磁盘IO等,就需要用到node_export工具安装部署在被测服务器上。
node_export的安装:
- 第一步: 上传安装包到被测服务器,并解压: tar -xzvf node_exporter-1.1.1.linux-amd64.tar.gz
- 第二步:启动这个服务: ./node_exporter &
- 第三步: 验证这个node服务是否启动:http://192.168.61.137:9100/metrics ,可以看到metrics 这个路径,点击进去就是收集到的硬件监控的结果。
- node_exporter 启动后,默认端口是 9100 ,注意端口需要开放,不然访问不到。
但是这个metric的数据查看起来非常不直观并且也不方便进行持久化存储,所以我们要把node_export的数据全部要传到prometheus数据库里去存储。
Prometheus存储export收集的数据:
思考问题:Node_export从被测服务器收集到数据,那么Prometheus如何知道这个node_exporter收集的数据呢?这个时候,我们需要修改prometheus的配置文件。步骤如下:
- 第一步:prometheus需要修改配置文件,把exporter数据收集回来放到prometheus的数据库里。
- 修改在prometheus的解压根目录下的 prometheus.yml 配置文件,新增内容如下:
在Scrape_configs节点下增加(注意写法)
- job_name: 'server-data'
static_configs:
- targets: ['192.168.61.136:9100']
注意:
1、job_name :这个名字只要不重复,自己随便取,但是建议见名知意;server_data 或者node_export都可以
2、如果要加多个目标机器,逗号隔开就可以: - targets: ['192.168.61.136:9100','192.168.61.137:9100'];
- 第二步: 重启prometheus服务: ./promethues &
- 第三步:prometheus页面上查看一下 监控节点是否显示:选择status--> target:
- http://192.168.61.130:9090/targets :会出现刚刚配置的节点,并状态是up的,点击可以跳转到node的web页面

4、Prometheus+ Grafana集成
因为prometheus自己的监控数据看起来不够直观,所以我们会使用grafana进行展示。
注意:确定安装Prometheus和Grafana的两个服务器之间的网络是通的,可以放在同一个机器上进行安装。
在grafana的访问页面上做如下配置:
- 第一步:添加数据源: prometheus
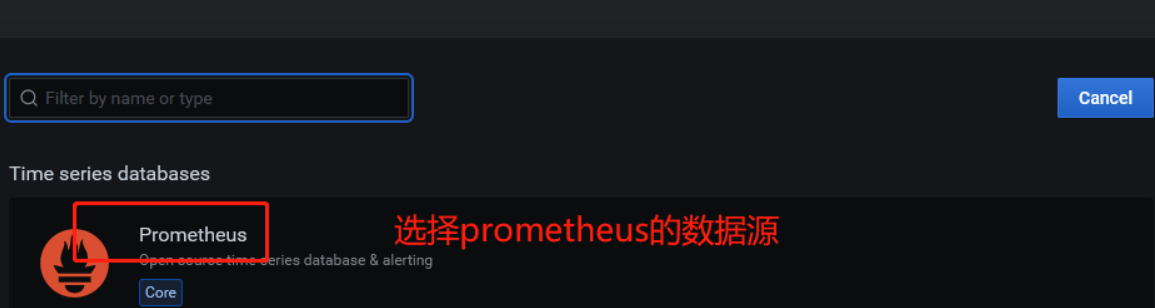
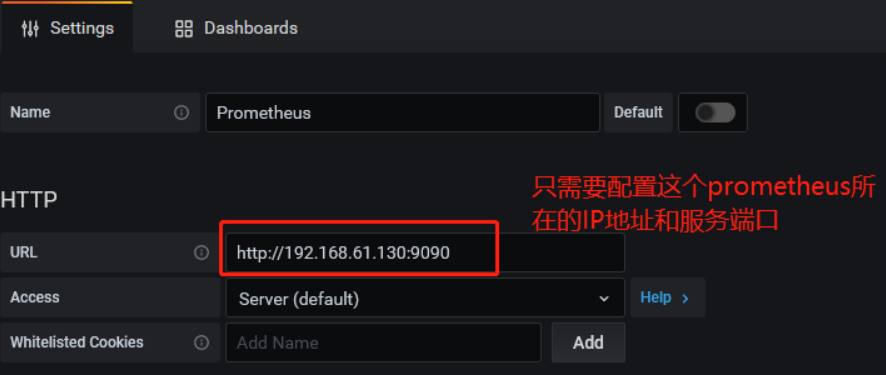
第二步:导入grafana的模板 :配置面板 12884
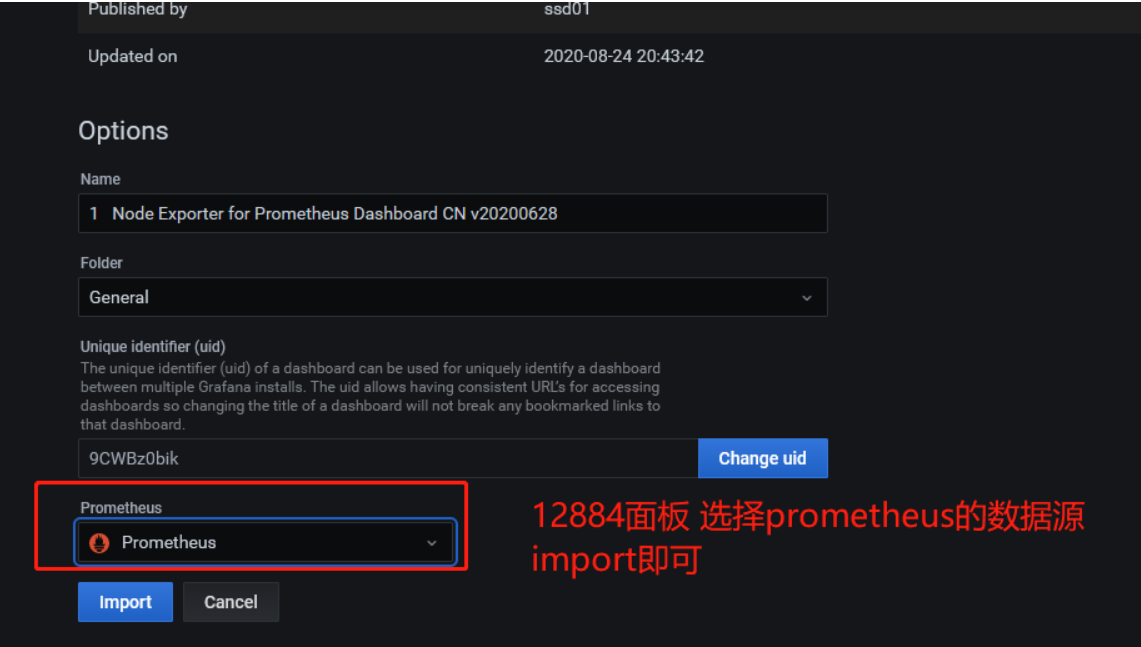
第三步: 打开面板后,可以查看服务器的硬件的数据监控,如下图。
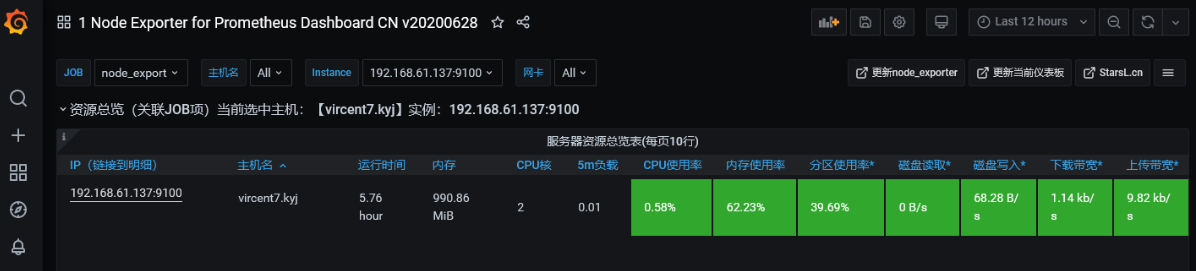
以上就完成了Prometheus+Grafana+Node_Export的部署和方案落地了。
如果要进行其他的数据监控,替换exporter文件就可以了。Prometheus里的配置文件也做对应的修改即可。
- 比如监控数据库:mysqld_exporter-0.12.1.linux-amd64.tar
- 监控Nginx:nginx-vts-exporter-0.10.3.linux-amd64.tar
- 监控redis数据库的:redis_exporter-v1.17.1.linux-amd64.tar
你想用 Prometheus监控平台,去监控其他的服务, 可以去找服务对应的 exporter,按照安装说明,进行配置。
方案的常见的问题以及其解决办法:
监控界面不显示数据:
很多同学配置完成后Prometheus的页面不会出现数据,排查步骤如下:
1、数据源的配置出现连接不上问题,报错连接失败: 基本上是服务启动的问题或者prometheus的配置文件的问题,可以检查一下;
2、数据源的配置没有出现连接不上问题,所有的pannel都是 N/A None的空数据:
- 1)可能是时间跨度太小,近期没有数据:可以点击右上角时间范围可以选择更大的时间范围,观察数据;
- 2)数据库服务器、grafana机器、被监控机器,时间相差非常大:可以去各个服务器上同步时间。
欢迎来到testingpai.com!
注册 关于