你在学习 python 自动化测试吗?听过 requests 库吗?tablib 是 requests 库常年维护的一个可以操作 Excel 等多种文件格式,将他们变成一种通用数据集的第三方库。
tablib 支持的主要数据格式有:
- xls, 老版 office 的 excel 文件格式;
- xlsx系列,新版 office 文件格式;
- json
- yaml
- html
- csv
- df,pandas 的 DataFrame, 需要安装 pandas
也就是说,tablib 能把不同格式的数据转化成一种通用的关系型数据格式,然后再各个格式之间无缝切换。什么叫关系型数据格式呢?比如:
- MySQL 数据,每行数据对应着一个字段名。你可以通过这个库将数据库查询到的数据轻松存入 Excel。
- Excel 数据,每行数据都有一个 header。
- json, 数据分为 key 和 value
- 上面提到的都类似。
tablib 这种通用数据格式的特性解决了以前一些 Excel 操作库的一些问题。
操作 Excel 的几个常用库
- xlrd
- openpyxl
这些库都是非常优秀的库,限制性也有:
- xlrd 的问题。他只能读,不能写。要写还得另外装库。
- openpyxl 的问题。只支持 xlsx 系列的读写。因为现在大多使用这种 Excel 格式,所以这个问题其实可以忽略,但如果你的 office 软件比较老,只能用 xls 格式,这个库就用不了了。
tablib 的安装
- 安装 pip install tablib
- 导入 import tablib
核心概念
tablib.Dataset() # 相当于 Excel 中的 sheet
tablib.Databook() # 相当于 Excel 中的 workbook 工作簿
Dataset 快速入门
先看一个小例子:
| url | method | expected |
|---|---|---|
| lemon.ke.qq.com | get | 成功 |
| lemonban.com | post | 成功 |
url, method, expected 是一个表的表头 header,其实就是每一列的名字,在数据库里我们称为字段名。下面的行都是数据。
想要创建一个 Excel 非常的简单,只需要准备你需要的数据 data, 表头 header 和 表的名字 title:
import tablib
# 表各列的标题 header
headers = ['url', 'method', 'expected']
# 需要存到 excel 的数据
data_list = [
['https://lemon.ke.qq.com', 'get', '成功'],
['https://lemonban.com', 'post', '成功']
]
# 生成数据
data = tablib.Dataset(*data_list, headers=headers,title='测试用例')
print(data)
打印的结果是这样的:

保存为 excel
要保存为 excel 文档,只需要像操作普通的文件一样读写就可以了,写入 data.xls 或者 data.xlsx 属性里面的数据:
with open('demo.xls', 'wb') as f:
f.write(a.xls)
with open('demo.xlsx', 'wb') as f:
f.write(a.xlsx)
注意:模式需要用二进制模式 wb
保存之后的结果是这样的:
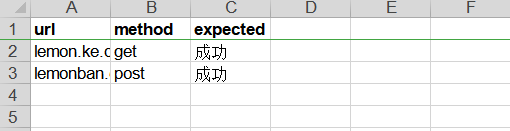
Databook
Databook 就是类似工作簿的概念,所以 Databook 需要的参数实际上就是上文中的 DataSet。如果一个 Excel 里只有一个表,用 DataSet 就够了,如果有多个表:
book = tablib.Databook([data, data2])
with open('demo_book.xls', 'wb') as f:
f.write(book.xls)
表格导入:import_set
说完 Excel 的写操作, 接下来是读操作, 读取一个 excel 文件也是和普通文件读写类似,调用 import_set 方法:
with open('demo.xls', 'rb') as f:
# 接受 2 个参数,读出来的数据和读取的文件格式
data = tablib.import_set(f.read(), 'xls')
print(data)
# 或者采用第二种方式
with open('demo.xls', 'rb') as f:
data = tablib.DataSet().load(f.read(), 'xls')
print(data)
获取数据进行自动化测试
用一个例子来实战,获取 excel 文件里的数据,执行自动化测试程序:
def api_tester(url, method, expected):
print("正在测试{},请求方法{}, 预期结果{}".format(
url, method, expected))
with open('demo.xls', 'rb') as f:
# 接受 2 个参数,读出来的数据和读取的文件格式
data = tablib.import_set(f.read(), 'xls')
print(data)
for i in data:
api_tester(*i)
导入book
和 DataSet 的操作一样的:
with open('demo.xls', 'rb') as f:
# 接受 2 个参数,读出来的数据和读取的文件格式
data = tablib.import_book(f.read(), 'xls')
print(data)
# 或者采用第二种方式
with open('demo.xls', 'rb') as f:
data = tablib.DataBook().load(f.read(), 'xls')
print(data)
总结
这篇我们熟悉了 tablib 的核心概念:
- DataBook
- DataSet
- 读取, import_set, import_book
- 写入, write
下篇我们将行列和数据操作,以及它的一些特性。
欢迎来到testingpai.com!
注册 关于