目录:
为什么要进行参数化?
参数化的类型:
文件参数化
数据库参数化
其它参数化
为什么要进行参数化?
用户在录制脚本过程中,填写提交了一些数据,这些操作都被记录到了脚本中。当多个虚拟用户运行脚本时,都会提交相同的记录,这样不符合实际的运行情况,而且有可能引起冲突。为了真实的模拟实际环境,需要各种各样的输入。
参数化包含以下两项任务:
①在脚本中用参数取代常量值。
②设置参数的属性以及数据源。
文件参数化
1、选中需要参数化的内容,点击右键,选择 Replace with a parameter

2、在“参数名”框中键入参数的名称,或从列表中选择一个现有的参数名。
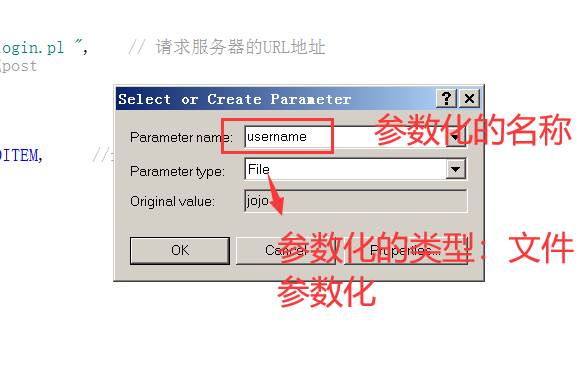
3、在从“参数类型”列表中选择参数类型。

4、点击按钮如下:

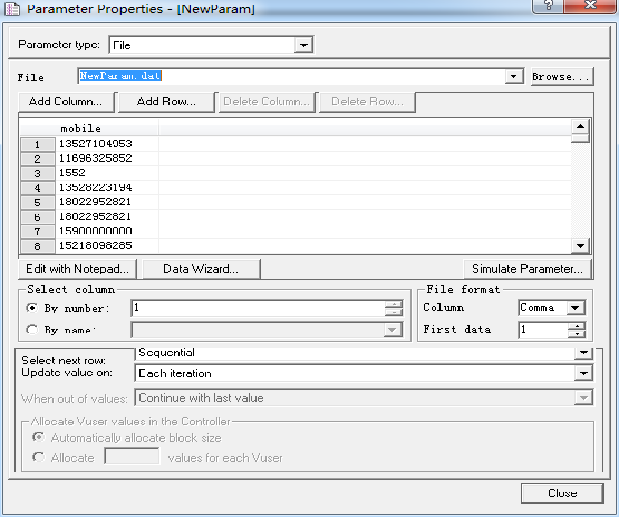
5、参数化设置属性界面如下:

参数取值的策略:
Select next row【选择下一行】

Update value on【更新时的值】
每次迭代(Each iteration) :每次迭代时取新的值,假如50个用户都取第一条数据,称为一次迭代;完了50个用户都取第二条数据,后面以此类推。
每次出现(Each occurrence):每次参数时取新的值,这里强调前后两次取值不能相同。
只取一次(once) :参数化中的数据,一条数据只能被抽取一次。(如果数据轮次完,脚本还在运行将会报错)
组合取值的方式如下:

数据库参数化
步骤:
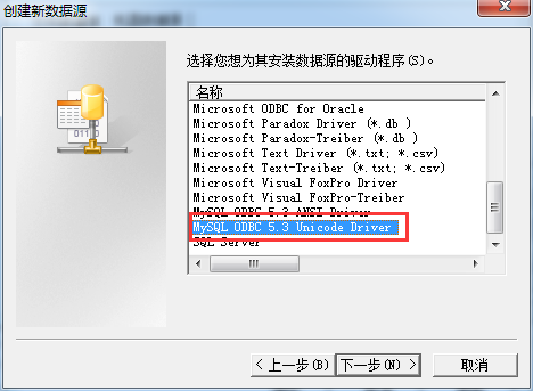
1、安装mysql odbc驱动,版本5.3就可以
2、在文本参数化页面,单击Data Wizard按钮,在弹出的对话框中选择“specify sql statement manu”,并点击“下一步”按钮,出现如下图:

3、点击“create”按钮,选择“机器数据源”
4、点击“新建”按钮,选择“系统数据源”


5、选择一个数据源的驱动程序
6、点击“完成”按钮,出现连接数据库的页面

7、选择刚才填写的数据源名称
8、把数据源配置到了Database Query Wizard中


9、在图中的SQL处输入想要查找的SQL语句,点击“Finish”按钮
10、已经把查询出来的数据导入了

其它参数化
Data/Time:在需要参数化日期的地方使用此类型
Group Name:使用该虚拟用户所在的Vuser Group名称来代替参数化
Iteration Number:使用脚本执行的当前迭代次数来代替参数化
Load Generator Name:使用产生vuser负载的机器名称来代替参数化
Random Number:使用一个随机数来代替参数化
Unique Number:使用一个唯一的整数来代替参数化(用于批量生成不一样的值)

User Defined Functions:扩展接口,可从用户开发的DLL文件中提取
Vuser ID使用虚拟用户的ID来代替参数化
XML:提供对XML格式数据的支持。可以从XML中读取数据进行参数化
主要的参数化就这样了,多去动手实践,才能更好的理解
欢迎来到testingpai.com!
注册 关于